캐글 타이타닉 3. EDA - Sex(성별)
f, ax = plt.subplots(1, 2, figsize=(18, 8))
#도화지(fig)를 만들고 ax를 1x2로 나눔(subplots)
df_train[['Sex', 'Survived']].groupby(['Sex'], as_index=True).mean().plot.bar(ax=ax[0])
ax[0].set_title('Survived vs Sex')
#df_train의 Sex와 Survived칼럼만 가져와 Sex에 따라 나눈 평균을 구해 ax[0]에 바플랏을 그림
sns.countplot('Sex', hue='Survived', data=df_train, ax=ax[1])
ax[1].set_title('Sex: Survived vs Dead')
#df_train의 Sex에 따라 x축을 그리고 Survived여부에 따라 색을 달리 해 ax[1]에 카운트플랏을 그림
plt.show() #전체 그림(도화지)을 보여줌

df_train[['Sex', 'Survived']].groupby(['Sex'], as_index=True).mean().sort_values(by='Survived', ascending=False)
#위 그래프의 왼쪽 데이터로 바플랏을 그리지 않고 sort_values를 이용해 표로 보여줌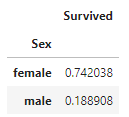
- as_index=True로 설정하면 왼쪽처럼 groupby 칼럼이 인덱스가 됨.
- as_index=False로 설정하면 Sex가 인덱스가 아닌 하나의 칼럼으로 존재함
- 여성의 대부분(74%)은 생존했으나 남성의 대부분(약 81%)은 사망했음 : 성별에 따라 생존확률이 다른 경향이 있음
sns.factorplot(x='Sex', y='Survived', col='Pclass', data=df_train, size=9)
#df_train의 Sex, Survived를 활용해 그림을 그리되, Pclass에 따라 컬럼을 나눔
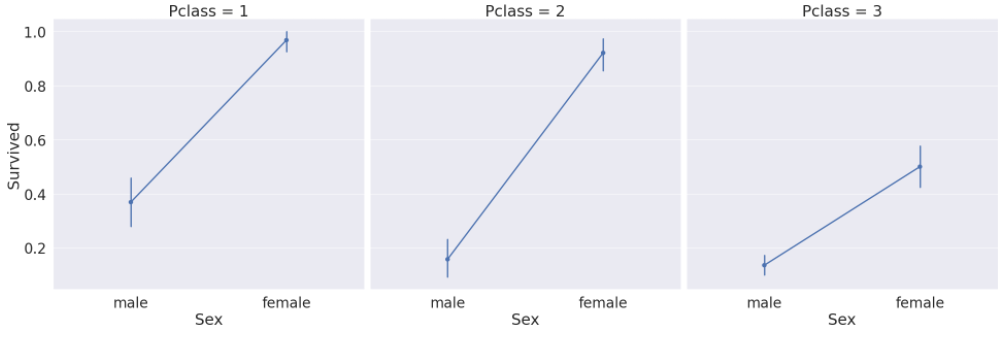
- 여기서 col을 hue로 바꾸면 위의 세 그래프를 하나의 그래프에 담음(Pclass에 따라 색 구분)
캐글 타이타닉 4. EDA - Age
fig=plt.figure(figsize=(9, 5)) #사이즈가 (9, 5)인 도화지를 만듦
sns.kdeplot(df_train[df_train['Survived'] == 1]['Age'])
sns.kdeplot(df_train[df_train['Survived'] == 0]['Age'])
plt.legend(['Survived', 'Dead'])
#도화지에 df_train의 Survived에 따른 Age의 kdeplot을 그리고 레전드를 넣어줌
plt.show() #도화지 보여주기
- kdeplot : Kernel Density Estimation, 데이터 분포가 어떻게 되는지에 대한 추정 그래프.
- histplot을 그린 뒤 그 값 분포를 곡선 형태로 바꾼 것이라 생각하면 됨. histplot은 왼쪽 그래프처럼 두 그래프가 겹치면 값을 정확히 알기 힘드나 kdeplot은 겹쳐도 그 형태를 이해하는 데 지장이 없음
- Age가 어린 경우 생존확률이 더 높아보인다
change_age_range_survival_ratio = [] #빈 리스트를 만듦
for i in range(1, 81):
change_age_range_survival_ratio.append(df_train[df_train['Age'] < i]['Survived'].sum()/ len(df_train[df_train['Age'] < i]['Survived']))
#Age의 최솟값이 0.4, 최댓값이 80이므로 i범위는 1~80
#Age보다 i가 더 큰 경우 Survived의 '합'을 '개수(길이)로 나눈 값'을 빈 리스트에 append
plt.figure(figsize = (7, 7))
plt.plot(change_age_range_survival_ratio)
plt.title('Survival rate change depending on range of Age', y=1.02)
plt.xlabel('Range of Age(0~x)')
plt.ylabel('Survival Rate')
plt.show() #리스트의 그래프를 도화지에 바로 그려 보여줌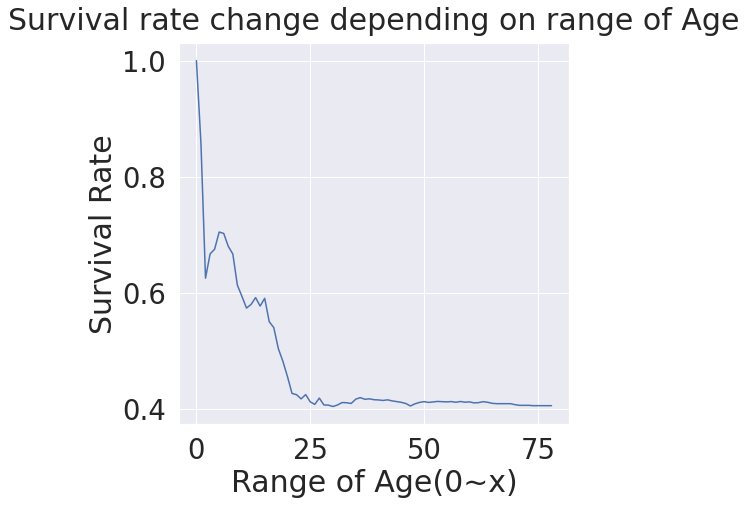
- change_age_range_survival_ratio 라는 리스트 요소들 하나하나의 값을 생각해 보아야 함
(i가 1인 경우 df_train의 Age가 1보다 작은 0.4살 등등의 Survived의 합을 그 길이로 나눈 것이 1에 수렴함 == 1세 미만은 모두 생존함)
(점점 1에서 멀어짐 == 나이가 많아질수록 생존율이 줄어드는 경향이 있음 == 나이가 어릴수록 생존확률이 높은 경향이 있음)
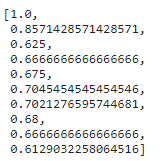
- 실제로 `change_age_range_survival_ratio[0:10]`의 값을 살펴보면 왼쪽과 같음.
- 이는 위에서 내린 추정과 일치
'STUDY' 카테고리의 다른 글
| 파이썬 스터디 3주차(백준) (0) | 2022.01.25 |
|---|---|
| 파이썬 스터디 2주차(머신러닝) (0) | 2022.01.24 |
| 파이썬 스터디 2주차(백준) (0) | 2022.01.11 |
| 파이썬 스터디 1주차(머신러닝) (3) | 2022.01.11 |
| 파이썬 스터디 1주차(백준, 캐글) (4) | 2022.01.07 |


