https://book.naver.com/bookdb/book_detail.nhn?bid=16238302
파이썬 머신러닝 완벽 가이드
자세한 이론 설명과 파이썬 실습을 통해 머신러닝을 완벽하게 배울 수 있습니다!《파이썬 머신러닝 완벽 가이드》는 이론 위주의 머신러닝 책에서 탈피해 다양한 실전 예제를 직접 구현해 보면
book.naver.com
4. 분류
08. 분류 실습 - 캐글 산탄데르 고객 만족 예측
import numpy as np; import pandas as pd
import matplotlib.pyplot as plt; import matplotlib
#데이터 불러오기
cust_df = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/santander/train_santander.csv', encoding='latin-1')
#타겟 값 분포 알아보기
print(cust_df['TARGET'].value_counts())
unsatisfied_cnt = cust_df[cust_df['TARGET'] == 1].TARGET.count()
total_cnt = cust_df.TARGET.count()
print(f"불만족 비율은 {unsatisfied_cnt/total_cnt:.2f}")
- 대부분이 만족(0)이고 일부가 불만족(1)이기 때문에 정확도보다 roc-auc로 성능 평가 (참고로 roc-auc는 이진 분류 성능 평가를 위해 사용되는 지표로, auc는 roc곡선 밑의 면적을 구하는 것을 말함!)
#이상치 처리, 식별자 칼럼 삭제
cust_df['var3'].replace(-999999, 2, inplace=True)
cust_df.drop('ID', axis=1, inplace=True)
#피처/레이블 분리
X_features = cust_df.iloc[:, :-1] #타겟 칼럼만 제외
y_labels = cust_df.iloc[:, -1] #타겟 칼럼만
print(f"피처 데이터 shape: {X_features.shape}") #ID칼럼, 타겟 칼럼을 제외했으므로 371->369
#학습/테스트 데이터 분리, 값 분포 확인
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_features, y_labels, test_size=0.2, random_state=0)
train_cnt = y_train.count(); test_cnt = y_test.count()
print(f"학습 세트 Shape: {X_train.shape}, 테스트 세트 Shape: {X_test.shape}")
print("학습 세트 레이블 값 분포 비율"); print(y_train.value_counts()/train_cnt)
print("테스트 세트 레이블 값 분포 비율"); print(y_test.value_counts()/test_cnt)
- 학습 데이터 세트, 테스트 데이터 세트 모두 불만족 비율이 4%로 고루 나누어 졌음을 확인
(참고 : 테스트 데이터 세트를 XGBoost 평가 데이터 세트로 사용하면 과적합 가능성이 커질 수 있음..!)
from xgboost import XGBClassifier
from sklearn.metrics import roc_auc_score
#xgboost모델학습
xgb_clf = XGBClassifier(n_estimators=500, random_state=156)
xgb_clf.fit(X_train, y_train, early_stopping_rounds=100, eval_metric="auc", eval_set=[(X_train, y_train), (X_test, y_test)])
#roc_auc 예측
xgb_roc_score = roc_auc_score(y_test, xgb_clf.predict_proba(X_test)[:, 1], average='macro')
print(f"ROC AUC: {xgb_roc_score:.4f}")
- n_estimators는 500으로 설정해 주었으나 early_stopping_rounds가 100이었으므로 178에서 100번 반복했을 때 값이 나아지지 않아 278까지만 반복되고 멈춘 것
from sklearn.model_selection import GridSearchCV
xgb_clf = XGBClassifier(n_estimators=100) #테스트 수행속도 향상을 위해 조정
params = {'max_depth': [5, 7], 'min_child_weight': [1, 3], 'colsample_bytree': [0.5, 0.75]}
gridcv = GridSearchCV(xgb_clf, param_grid=params, cv=3)
gridcv.fit(X_train, y_train, early_stopping_rounds=30, eval_metric="auc", eval_set=[(X_train, y_train), (X_test, y_test)])
print('GridSearchCV 최적 파라미터:', gridcv.best_params_)
xgb_roc_score = roc_auc_score(y_test, gridcv.predict_proba(X_test)[:, 1], average='macro')
print(f"ROC AUC: {xgb_roc_score:.4f}")
- 하이퍼 파라미터를 적용해주니 이전의 roc-auc(0.8419)보다 높은 값(0.8461)을 보임. 이렇게 나온 하이퍼 파라미터를 토대로 다시 최적화를 해볼 수 있음
#다른 하이퍼 파라미터 변경/추가해 다시 최적화 진행
xgb_clf = XGBClassifier(n_estimators=1000, random_state=156, learning_rate=0.02, max_depth=5, min_child_weight=1, colsample_bytree=0.5, reg_alpha=0.03)
xgb_clf.fit(X_train, y_train, early_stopping_rounds=200, eval_metric="auc", eval_set=[(X_train, y_train), (X_test, y_test)])
xgb_roc_score = roc_auc_score(y_test, xgb_clf.predict_proba(X_test)[:, 1], average='macro')
print(f"ROC AUC: {xgb_roc_score:.4f}")
- n_estimators를 1000, early_stopping_rounds를 200, learning_rate를 0.02로 바꾸니 오히려 이전보다 roc auc 값이 떨어졌음
(책에서는 값이 올랐었는데.. 음..ㅠ.. 뭐 그래도 책에 나온 값(0.8456)보다는 더 좋은 결과값이긴 하다.)
- xgboost는 GBM보단 빠르나 GBM기반이기 때문에 꽤 긴 수행시간이 요구됨
- 모델의 각 피처 중요도를 그래프로 나타내면 다음과 같다.

- var38과 var15 피처의 중요도가 타 피처에 비해 큼을 알 수 있음
from lightgbm import LGBMClassifier
lgbm_clf = LGBMClassifier(n_estimators=500)
#LGBMClassifier 모델 학습
evals=[(X_test, y_test)]
lgbm_clf.fit(X_train, y_train, early_stopping_rounds=100, eval_metric="auc", eval_set=evals, verbose=True)
lgbm_roc_score = roc_auc_score(y_test, lgbm_clf.predict_proba(X_test)[:, 1], average='macro')
print(f"ROC AUC: {lgbm_roc_score:.4f}")
from sklearn.model_selection import GridSearchCV
lgbm_clf = LGBMClassifier(n_estimators=200)
#하이퍼 파라미터 튜닝
params = {'num_leaves': [32, 64], 'max_depth': [128, 160], 'min_child_samples': [60, 100], 'subsample': [0.8, 1]}
gridcv = GridSearchCV(lgbm_clf, param_grid=params, cv=3)
gridcv.fit(X_train, y_train, early_stopping_rounds=30, eval_metric="auc", eval_set=[(X_train, y_train), (X_test, y_test)])
print("GridSearchCV 최적 파라미터:", gridcv.best_params_)
lgbm_roc_score = roc_auc_score(y_test, gridcv.predict_proba(X_test)[:, 1], average='macro')
print(f"ROC AUC: {lgbm_roc_score:.4f}")
lgbm_clf = LGBMClassifier(n_estimators=1000, num_leaves=32, subsample=0.8, min_child_samples=100, max_depth=128)
evals = [(X_test, y_test)]
lgbm_clf.fit(X_train, y_train, early_stopping_rounds=100, eval_metric="auc", eval_set=evals, verbose=True)
#파라미터 적용해 roc auc 다시계산
lgbm_roc_score = roc_auc_score(y_test, lgbm_clf.predict_proba(X_test)[:, 1], average='macro')
print(f"ROC AUC: {lgbm_roc_score:.4f}")
- roc auc는 최적의 하이퍼 파라미터 적용 전 0.8396, 적용 후 0.8442로 측정됨
09. 분류 실습 - 캐글 신용카드 사기 검출
- 언더 샘플링, 오버 샘플링
- 이상 레이블을 가지는 데이터 건수가 정상 데이터 건수에 비해 너무 적을 때 예측 성능의 문제가 발생할 수 있음. 이를 해결하기 위해선 적절한 학습 데이터를 확보해야 하는데, 언더 샘플링과 오버 샘플링이 대표적인 방법.
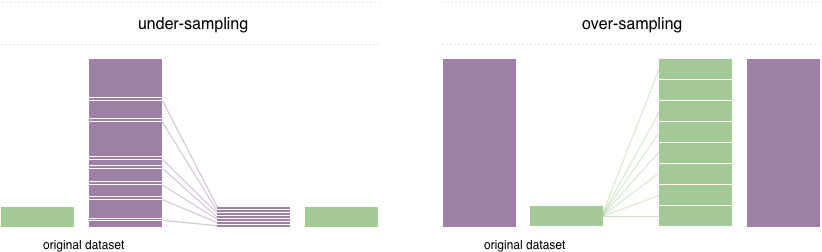
- 언더 샘플링 : 많은 레이블을 가진 데이터 세트를 적은 레이블을 가진 데이터 세트 수준으로 만듦. 너무 많은 데이터를 감소시켜 정상 레이블의 제대로 된 학습을 방해할 수 있음.
- 오버 샘플링 : 적은 레이블을 가진 데이터 세트를 많은 레이블을 가진 데이터 세트 수준으로 만듦. 대표적인 방법은 SMOTE(Synthetic Minority Over-sampling TEchnique). 이는 데이터 세트 내 개별 데이터들의 K 최근접 이웃(K Nearest Neighbor)을 찾아 데이터와 K개 이웃들의 차이를 값으로 만들어 기존 데이터와 차이나는 새 데이터를 생성하는 방식.
(데이터 1차 가공 과정 생략)
- 로지스틱 회귀는 선형 모델로, 대부분의 선형모델은 중요 피처 값이 정규분포 형태인 것을 선호함.

- 로그 변환은 데이터 분포가 심하게 왜곡되어 있을 때 주로 적용함. 넘파이의 log1p()함수로 간단히 변환 가능.
- 이상치 데이터(Outlier) : 전체 데이터 패턴에서 벗어난 이상 값을 가진 데이터. 주로 IQR(Inter Quantile Range)방식을 사용하며, 사분위값 편차를 이용해 박스 플롯으로 시각화를 한다. 주로 IQR에 1.5를 곱해 생성된 범위로 최댓/최솟값을 구한 뒤 이보다 크거나 작은 데이터를 이상치로 여기는 것.
(*사분위 : 전체 데이터를 값이 높은 순으로 정렬한 뒤 25%씩 구간을 분할하는 것. 25%구간을 Q1, 75%구간을 Q3이라 하며 Q1과 Q3간의 범위를 IQR이라 함)
- SMOTE는 imbalanced-learn 패키지의 SMOTE클래스로 구현 가능. 이때는 반드시 학습 데이터 세트만 오버 샘플링해야.
from imblearn.over_sampling import SMOTE
smote = SMOTE(random_state=0)
X_train_over, y_train_over = smote.fit_resample(X_train, y_train) #fit_sample이 안되길래 구글링해서 함..
print("SMOTE 적용 전 학습용 피처/레이블 데이터 세트: ", X_train.shape, y_train.shape)
print("SMOTE 적용 후 학습용 피처/레이블 데이터 세트: ", X_train_over.shape, y_train_over.shape)
print("SMOTE 적용 후 레이블 값 분포: ", pd.Series(y_train_over).value_counts())
- smote.fit_sample 적용 전후 값 비교. 데이터가 증식되었음을 확인할 수 있음
#로지스틱 회귀
lr_clf = LogisticRegression()
get_model_train_eval(lr_clf, ftr_train=X_train_over, ftr_test=X_test, tgt_train=y_train_over, tgt_test=y_test)
precision_recall_curve_plot(y_test, lr_clf.predict_proba(X_test)[:, 1]) #정밀도-재현율 커브
- SMOTE를 적용하면 재현율은 높아지나 정밀도는 낮아지는 것이 일반적임. 이에 재현율 증가율을 높이고 정밀도 감소율을 낮추도록 데이터를 증식하는 것이 좋음.
10. 스태킹 앙상블
스태킹 : 개별적인 여러 알고리즘을 서로 결합해 예측결과를 도출하는 것.
- 개별 알고리즘의 예측 결과 데이터 세트를 최종 메타 데이터 세트로 만들어 별도의 ML 알고리즘으로 최종 학습을 수행하고 테스트 데이터를 기반으로 최종 예측을 수행하는 방식. 이를 메타 모델이라 함.
- 스태킹은 개별적인 기반 모델과 개별 기반 모델의 예측 데이터를 학습 데이터로 만들어 학습하는 최종 메타모델 두 종류의 모델이 필요함. 이에 많은 개별 모델이 필요하며 성능이 비슷한 모델들을 결합해 더 나은 성능 향상을 이루고자 함.

- 기본 스태킹 모델
#스태킹 앙상블
from sklearn.datasets import load_breast_cancer
cancer_data = load_breast_cancer()
X_data = cancer_data.data
y_label = cancer_data.target
X_train, X_test, y_train, y_test = train_test_split(X_data, y_label, test_size=0.2, random_state=0)
#스태킹에 사용할 머신러닝 알고리즘 클래스
knn_clf = KNeighborsClassifier(n_neighbors=4)
rf_clf = RandomForestClassifier(n_estimators=100, random_state=0)
dt_clf = DecisionTreeClassifier()
ada_clf = AdaBoostClassifier(n_estimators=100)
knn_clf.fit(X_train, y_train); rf_clf.fit(X_train, y_train);
dt_clf.fit(X_train, y_train); ada_clf.fit(X_train, y_train)
knn_pred = knn_clf.predict(X_test); rf_pred = rf_clf.predict(X_test)
dt_pred = dt_clf.predict(X_test); ada_pred = ada_clf.predict(X_test)
print(f"KNN 정확도: {accuracy_score(y_test, knn_pred):.4f}")
print(f"랜덤포레스트 정확도: {accuracy_score(y_test, rf_pred):.4f}")
print(f"결정트리 정확도: {accuracy_score(y_test, dt_pred):.4f}")
print(f"에이다부스트 정확도: {accuracy_score(y_test, ada_pred):.4f}") #출력1
#스태킹으로 만든 데이터세트를 학습, 예측할 최종 모델
lr_final = LogisticRegression(C=10)
pred = np.array([knn_pred, rf_pred, dt_pred, ada_pred])
pred = np.transpose(pred)
lr_final.fit(pred, y_test)
final = lr_final.predict(pred)
print(f"최종 메타 모델의 예측 정확도: {accuracy_score(y_test, final):.4f}") #출력2
(출력1)
- 반환된 예측 데이터 세트는 1차원 형태의 ndarray. 결과를 행 형태로 붙인 뒤 np.transpose()로 행과 열 위치를 바꾼 ndarray로 변환(`pred`)
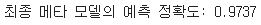
(출력2)
- 스태킹이 무조건 개별 모델보다 높은 정확도를 갖는 건 아님!
- CV세트 기반 스태킹

- 과적합 개선을 위해 최종 데이터세트를 만들 때 교차검증 기반으로 예측된 결과 데이터세트 이용
- 각 모델별 원본 학습/테스트 데이터를 예측한 결과값을 기반으로 메타 모델을 위한 학습용/테스트용 데이터 생성
- 1에서 생성한 학습용 데이터를 스태킹 형태로 합쳐 메타 모델이 학습할 데이터세트 생성. 테스트용 데이터도 마찬가지로 진행. 메타 모델이 학습 데이터세트와 원본 레이블 데이터로 학습한 뒤 최종적인 테스트 데이터 세트를 예측하고 원본 테스트 데이터의 레이블 데이터 기반 평가
- 핵심은 개별 모델에서 메타 모델(2차 모델)에 사용될 학습용/테스트용 데이터를 교차검증으로 생성하는 것
- 스태킹을 이루는 모델은 파라미터를 튜닝한 상태에서 스태킹 모델로 만드는 것이 일반적.
- 분류 뿐만 아니라 회귀에도 적용 가능
11. 정리
- 대부분의 앙상블 기법은 결정트리 기반의 약한 학습기를 결합함
- 결정트리는 정보 균일도에 기반한 규칙 트리를 만들어 예측 수행
- 앙상블은 대표적으로 배깅과 부스팅으로 구분됨. 배깅은 학습 데이터를 (중복 허용)다수 세트로 샘플링해 다수의 약한 학습기로 학습하고 최종 결과를 결합해 예측. 대표가 랜덤포레스트. 부스팅은 학습기들이 순차적으로 학습하며 틀린 데이터에 가중치를 부여하며 정확도를 높임. GBM. XGBoost, LightGBM등이 있음.
- XGBoost와 LightGBM은 사이킷런 래퍼 클래스를 제공해 다른 Estimator 클래스들과 동일하게 사용 가능
- 스태킹은 여러 모델들이 생성한 예측 데이터를 기반으로 최종 메타 모델이 학습할 학습 데이터 세트와 예측할 테스트 데이터 세트를 재생성
회귀 군집화 텍스트분석 등등 갈 길이 멀다.. ^^ 목표는 14일까지 다 올리는건데 가능하려나 모르겠다
'STUDY' 카테고리의 다른 글
| 파이썬 스터디 10주차 (3) | 2022.03.18 |
|---|---|
| 파이썬 스터디 9주차 (0) | 2022.03.04 |
| 파이썬 스터디 4주차(머신러닝)(2) (1) | 2022.02.22 |
| 파이썬 스터디 4주차(머신러닝)(1) (0) | 2022.02.21 |
| 파이썬 스터디 7주차(캐글) (0) | 2022.02.18 |


