추후에 분리해서 올리던가 할 텐데, 일단은 ... 이 폼으로 작성해보도록 할게요.
1-1. https://disquiet.io/@shawnice/makerlog/1886 : (프로덕트 메이커의)데이터 제대로 보기 팁
🐋 프로덕트 메이커가 데이터 제대로 보는 방법 | Disquiet*
데이터 분석가 Harry(@김한빈)의 도움으로 이 글을 작성합니다유저가 우리 프로덕트를 사용하며 발생하는 데이터는 메이커에게 가장 소중한 자원이다. 특히 PMF를 찾는 여정에 있는 팀은 더더욱이
disquiet.io
- 데이터의 인사이트는 의미가 있어야 한다. 다른 말로, 데이터와 인사이트는 1)신뢰할 수 있고 2)목적과 목표에 맞고 3)회사의 비전과 맞닿아 있어야 한다.
- 데이터에서 찾은 인사이트는 실제 "사용할 수 있는"인사이트가 되어야 한다. 이는 인사이트를 1)문제에 기반한 것인지 2)당연한 것은 아닌지 3)당연한 것을 인지하지 못하고 있던 건 아닌지 4)액션플랜이 도출되는지 살펴보아야 한다는 뜻이 된다.
1-2. https://yozm.wishket.com/magazine/detail/1785/ : 데이터 드리븐 의사결정
Data-Driven하게 일하는 법 | 요즘IT
최근 ‘데이터 드리븐(Data-Driven)’을 추구하는 회사가 늘어나고 있습니다. 쿠팡처럼 데이터 드리븐으로 성공한 케이스가 나오고, 여러 매체에 관련 단어가 자주 노출되면서 기업 성공의 필수 요
yozm.wishket.com
데이터에서 가치를 창출하기 위한 방법론 1)Data-Informed(조직이 지표에 대해 파악하고 이해하는 것) 2)Data-Inspired(데이터로부터 유의미한 정보나 자료를 얻는 것) 3)Data-Driven(선택, 액션의 의사결정을 데이터로 하는 것)
- 데이터 드리븐 의사결정: '목표/지표 설정 - 기획/개발 - 액션 - 지표 결과 평가(피드백)'. 모든 아이디어가 데이터에 기반한 평가를 받기 때문에 '좋은' 의사결정이 이루어 질 수 있음, 유연한 상황대처가 가능하다는 장점이 있음. 리스크가 낮고 고점이 높은 방법론인 만큼, 훌륭한 의사결정 방식임.
- 데이터 드리븐의 핵심은 데이터가 아니라 목표 지표 설정 - 액션 - 피드백의 과정으로, 지표 성장이 서비스의 성장이라고 가정하는 것.
1-3. https://yozm.wishket.com/magazine/detail/1863/ : 데이터 분석가 현실(?)
데이터 분석가가 되어보니 중요한 것들 | 요즘IT
개발자, 디자이너, 기획자, HR, 오퍼레이션 등 대부분의 직무에서 우리가 일하기 전 예상했던 업무와 실제 업무에는 차이점이 존재합니다. 비즈니스는 빠르게 변화하기 때문에, 학생 때 배운 교
yozm.wishket.com
데이터 분석가: 데이터에 기반해 성공 확률이 높은 의사결정을 지속적으로 하도록 돕는 사람.
- 데이터 기반: 데이터가 흐르는 조직 구성(BI툴 도입, SQL교육과 데이터마트 구축, 주요 지표 인지), 정확한 상황해석, 목표 설정과 성과 측정(AB테스트), 지속성(비즈니스 사이클에 맞는 분석)
2. (개인)프로젝트
- 정규표현식을 사용해 원하는 컬럼들을 뽑아낸 뒤 리스트에 담았다. 그 결과 한참 전부터 뽑았던 'feature importance가 높은 컬럼들' 13개와 관련 컬럼, 승/패 구분을 위한 컬럼 등을 추가해 총 100000 x 19의 df를 만들 수 있었다.
- 널값이 하나 있길래 다른 부분과 대조하여 채워주었다.

- 위의 폼으로 보다가 좀 불편해서 아예 win여부에 따라 df를 나누었다.


- 승리 팀에서의 'nexusLost'컬럼 값은 모두 0이었고, 패배 팀에서의 'challenges.maxKillDeficit'값 또한 모두 0이었다. 이는 승리 팀에서만 'challenges.maxKillDeficit'값이 존재하며, 패배 팀에서만 'nexusLost'값이 존재한다는 의미이기도 하다!
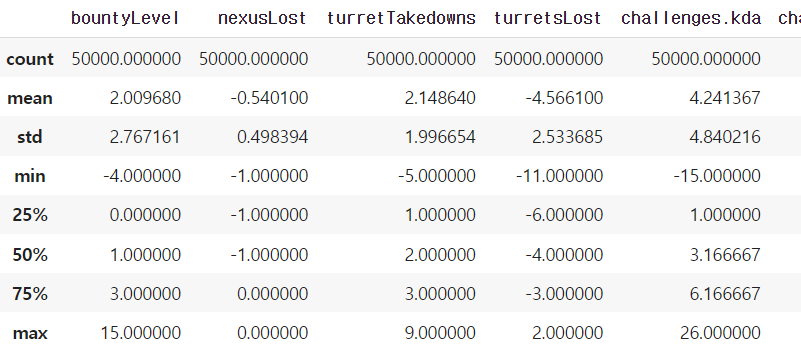
- 위 결과(mean과 std를 중점으로)로 플랏을 그려 한눈에 보고싶은데, barplot이 아니던가..? 계속 오류가 뜬다. 어떨 때 어떤 그래프를 그려야하는지도 다 까먹은 것 같다…
3. 공부했던 알고리즘들 개념위주 정리
http://www.yes24.com/Product/Goods/96402750 교재의 CH5 내용을 담고 있습니다.
Python으로 학습하는 컴퓨터 알고리즘 - YES24
Python으로 학습하는 컴퓨터 알고리즘
www.yes24.com
트리: 계층(부모-자식)관계를 표현하기 위해 사용하는 비선형 자료구조.
- 이진 트리: 각 노드가 두 개의 자식을 가질 수 있는 트리 형태. 자료 검색과 데이터 추가/삭제가 빠름. 전Full/완전Complete/포화Perfect/균형Balanced Binary Tree로 나뉨.
- 이진 검색 트리: '1)왼쪽 서브트리의 모든 노드가 루트노드보다 작고 2)오른쪽 서브트리의 모든 노드가 루트노드보다 크며 3)각 노드의 서브트리도 1과 2를 만족'하는 이진트리.
- 이진 트리 운행: 트리 순회(노드 방문, 값 인쇄) 방법으로 크게 1)전위(pre-order) 2)중위(In-order) 3)후위(Post-order)순회가 있음. 전위는 루트 -> 왼쪽 -> 오른쪽, 중위는 왼쪽 -> 루트 -> 오른쪽, 후위는 왼쪽 -> 오른쪽 -> 루트.
힙: 최대/최솟값을 빠르게 찾아내기 위해 고안된 완전이진트리 기반 자료구조.
- 1)부모 노드 키값 > 자식 노드 키값인 '최대 힙' 2)부모 노드 키값 < 자식 노드 키값인 '최소 힙' 두 종류로 나뉜다. 가장 높거나 낮은 우선순위의 노드가 루트노드에 위치하게 되는 것.
import heapq as hq #Heapq모듈로 힙 자료구조 사용 가능
heap = [1, 11, 25, 231, 77, 99, 33] #리스트
hq.heapify(heap) #iterable -> 힙 변환
print(heap, heap[0]) #[1, 11, 25, 231, 77, 99, 33] 1
hq.heappush(heap, 22) #힙에 22 삽입
out = hq.heappop(heap) #힙에서 가장 작은 값 반환
print(out, heap, heap[0]) #1 [11, 22, 25, 231, 77, 99, 33] 11- Heap는 기본적으로 최소 힙 구조를 따르며, heap[0]은 항상 가장 작은 요소를 반환함: 각 값에 -1을 곱해주면 최대 힙으로 사용 가능
우선순위 큐: 요소 삽입 시점에 제공되는 '관련 키'를 가지는 항목들의 컨테이너.
from queue import PriorityQueue
q = PriorityQueue() #우선순위 큐를 만듦
q.put((1, 'metamon'))
q.put((2, 'data'))
q.put((4, 'python'))
q.put((3, 'analysis'))
while not q.empty(): #q에 남은 게 없을 때까지
conts = q.get()
print(conts) #요소들 하나씩 get
#(1, 'metamon') #(2, 'data') #(3, 'analysis') #(4, 'python')집합: 중복되지 않고 순서가 없는 자료구조. {}(중괄호)로 작성. 차집합, 교집합, 합집합 등의 연산이 가능.
- 서로소 집합: 공통원소가 없는 두 집합.
4. https://yozm.wishket.com/magazine/detail/1815/?utm_source=stibee&utm_medium=email&utm_campaign=newsletter_yozm&utm_content=contents : UX(User Experience)
사용자 경험은 어떻게 측정할까요? | 요즘IT
사용자 경험은 기업에서 더 나은 비즈니스 성과를 위한 핵심 요소로 인식되고 있으며, 이에 따라 사용자 경험을 측정하고 관리하는 활동이 더욱 중요해지고 있습니다. 그렇지만 UX에 대해 위키
yozm.wishket.com
사용자를 만족시키는 UX의 구성요소: 사용성Usability, 유용성Usefulness, 감성Affect
- Usability, Usefulness, Affect -> 만족Satisfaction -> (브랜드에 대한)충성도Loyalty
- UX는 '사용자의 (제품이나 서비스에 대한) 반응'으로 다소 추상적인 개념이다. 이는 사용자의 1)주관적 데이터(직접 평가, 측정) 2)수행 데이터(상호작용 시의 행동 관찰, 측정) 3)생리적 데이터 세 가지 방식으로 알 수 있다.
- 로그데이터로 사용자 경험을 분석하는 방법에 대해서도 기술: 추후 제이림 프로젝트에 참조!
5. (제이림)프로젝트 진척상황 공유
- groupby로 한눈에 본 뒤 각 컬럼들의 value_counts()를 한다는 아이디어였는데, urlID컬럼값에 따라 groupby했을 때 (문자열 특성 때문인지) 같은 '숫자가 기록된 컬럼'들만 보이더라. 어떻게 해야할까? 막막하다...ㅎ
- 이전에 떠올렸던 아이디어처럼, 정말 urlID에 따라 나눈 총 10개의 df를 각각 분석하는 수밖에 없을까?
- 서브 프로젝트로 'https://www.data.go.kr/data/15086587/openapi.do'api를 활용해보려 하였으나, 불러온 결과 "활용할 수 없는"데이터임을 알 수 있었다. 이럴 거면 csv나 xml파일로 두었어도 괜찮으셨을 것 같은데 말이지... 시간낭비 한 것 같다.
- 점점 산으로 가고있어... 안돼ㅠ
6-1. https://www.kocca.kr/n_content/vol26/subp/special_nStory1.html : 콘텐츠 과다
N콘텐츠 vol.25
지친 자, 그리고 기다리는 자
www.kocca.kr
자신을 위한 (취향)리터러시가 필요함: 좋아하는 콘텐츠를 접하고 소비하는, '나를 위한' 미디어 환경 구축
- 이용자가 주도하는 미디어 생태계가 만들어진 지금, 현재의 미디어는 이용자의 관심이 희소한 자원으로 작용함
- 콘텐츠 포모(Fear Of Missing Out, 소외되는 것에 대한 두려움)증후군 등, 콘텐츠 증가로 인한 피로감
- OTT의 보편화로 인한 '실시간성' 의미 퇴색, SNS의 활성화로 인한 원치 않는 콘텐츠 접촉/소비량 증가
- https://www.kocca.kr/n_content/vol26/subp/special_nStory4.html : 콘텐츠 해독에 관하여
- 리뷰형 요약 콘텐츠와 숏폼 콘텐츠가 주목받는 이유: 콘텐츠의 범람.
- 디지털 리터러시 1)정보 활용, 생성 2)기기, 소프트웨어 활용 3)의사소통, 문제해결 4)정보윤리 기반 시민의식
6-2. https://www.kocca.kr/n_content/vol26/subp/special_nStory3.html : 게임을 통한 힐링
N콘텐츠 vol.25
게임으로 쉬어가는 사람들
www.kocca.kr
- "…이른바 '대세 콘텐츠'를 피상적으로라도 경험해야 현실 세계에서의 사회적 대화가 가능해진다는 분위기로 인해 이용자가 지갑을 강제로 여는 일이 일상화되고 있다. 경쟁이 격화되고 있는 콘텐츠 시장에서 거대 자본의 힘이 지극히 개인적인 콘텐츠 영역에서까지 소비 대열에서 이탈하면 안된다는 문화 강박증을 확산시키고 있는 셈이다."
'STUDY' 카테고리의 다른 글
| 취준로그 ver0.4 (0) | 2023.02.07 |
|---|---|
| 취준로그 ver0.3 (6) | 2023.02.01 |
| 취준로그 ver0.1 (0) | 2023.01.17 |
| 파이썬 스터디 ver3. 17주차 (2) | 2022.11.23 |
| 파이썬 스터디 ver3. 16주차 (3) | 2022.11.16 |



