2022.09.05~2022.09.09
구름 X 전주 ict이노베이션 스퀘어의 온라인 코딩교육 내용을 정리하였습니다.
학사일정으로는 시험기간이지만, 초과학기라 9학점 이수+시험보는 과목 없음으로 조금씩 조금씩 정리해나가려 합니다..! 빅데이터분석기사 실기 준비도 있고 (어쨌든)중간고사 준비겸 복습도 해야해서 학기중보다는 느리겠지만..ㅎㅠㅎ 화이팅
Tensorflow v2: tf.keras
- 분류 프로세스 수행
1. Prepare data(MNIST dataset)
#기본 세팅
import tensorflow as tf
from tensorflow.keras import datasets, models, layers, utils, losses, optimizers
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
#데이터셋 준비
(train_data, train_label), (test_data, test_label) = datasets.mnist.load_data()
print(train_data.shape), print(test_data.shape) #(60000, 28, 28), (10000, 28, 28)
import matplotlib.pyplot as plt
plt.imshow(train_data[0], cmap='gray') #첫번째 data의 이미지를 보여줌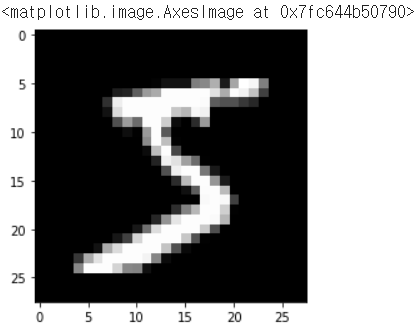
#데이터 정규화: 각 이미지는 0과 255 사이의 숫자로 이루어져 있음
print(train_data.min(), train_data.max()) #0 255
train_data = train_data.reshape(60000, 784) / 255.0
test_data = test_data.reshape(10000, 784) / 255.0
#이미지 크기를 28*28에서 1*784로 고침: 255로 나눠 픽셀값 0 ~ 1로 바꿈
print(train_data.shape) #(60000, 784)
#원핫 인코딩 수행
display(train_label) #원 레이블 값: array([5, 0, 4, ..., 5, 6, 8])
train_label = utils.to_categorical(train_label)
test_label = utils.to_categorical(test_label)
import pandas as pd #pandas df로 만들어 원핫이 잘 되었나 확인
pd.DataFrame(train_label).head(3)
2. Build the model & Set the criterion
#Sequential방법과 Functional방법 중 Sequencial 방법 사용 예정
model = tf.keras.models.Sequential() #레이어들의 시퀀스를 만듦: '도화지'
model.add(layers.Dense(input_dim=28*28, units=512, activation='relu',
kernel_initializer='he_uniform'))
model.add(layers.Dropout(0.2))
#Dense: 레이어 사이를 촘촘하게! #첫 hidden layer에는 input의 Dim을 써주어야 함
#units는 퍼셉트론 수 #HE초기화는 he_normal(정규), he_uniform(균등) 두가지가 있음
#Dropout: 0.2만큼 끎
model.add(layers.Dense(units=10, activation='softmax'))
#분류문제일 때에는 units에 클래스(레이블) 개수를 적어줌
#모델 세팅(컴파일)
model.compile(optimizer='adam', loss=losses.categorical_crossentropy,
metrics=['accuracy']) #보고싶은 성능지표를 문자열('')로 주어야 함3. Train the model
model.fit(train_data, train_label, batch_size=100, epochs=10)
#TF 버전2부터는 fit으로 모델학습 가능 #batch_size의 디폴트는 32
4. Test the model
result = model.evaluate(test_data, test_label, batch_size=100)
#test_X와 test_Y를 받아 evaluate실행: result에는 loss, test accuracy가 있음
print("Loss(cross-entropy):", result[0]) #Loss(cross-entropy): 0.05954774096608162
print("test accuracy:", result[1]) #test accuracy: 0.9821000099182129
model.summary() #만든 모델을 한눈에 볼 수 있도록 요약
- layers.flatten(): 데이터들을 펼쳐줌. 원 차원이 (60000, 28, 28, 3)이었다면 flatten 적용 후에는 (60000, 2352)가 되는 것
- Keras Callbacks API: 모델 학습 시작 이후부터는 학습 완료까지 사람이 할 수 있는 게 없으므로 '학습 조기종료, 학습 중 학습률 변화, 학습 중 모델 중간저장'등을 할 수 있도록 하는 것.
- 회귀 프로세스 수행
1. Prepare data(Boston dataset)
#기본 세팅
import pandas as pd; import numpy as np;
import matplotlib.pyplot as plt
from sklearn import datasets, preprocessing
#데이터셋 준비
print(datasets.load_boston().keys())
#dict_keys(['data', 'target', 'feature_names', 'DESCR', 'filename', 'data_module'])
x_data = datasets.load_boston().data
y_data = datasets.load_boston().target #집 가격
#train_test_split, 표준화scaler 사용
from sklearn import model_selection
train_data, test_data, train_label, test_label = model_selection.\
train_test_split(x_data, y_data, test_size=0.3, random_state=0)
print(train_data.shape, test_data.shape) #(354, 13) (152, 13)
print(train_label.shape, test_label.shape) #(354,) (152,)
sc = preprocessing.StandardScaler()
sc.fit(train_data) #스케일러를 train_data에 적용
train_data = sc.transform(train_data)
test_data = sc.transform(test_data)
pd.DataFrame(train_data).head()
2. Build the model & Set the criterion
import tensorflow as tf
from tensorflow.keras import datasets, utils
from tensorflow.keras import models, layers,\
activations, initializers, losses, optimizers, metrics
model = models.Sequential() #Sequential방법 사용: 레이어들의 도화지 생성
model.add(layers.Dense(input_dim=13, units=64, activation=None,
kernel_initializer=initializers.he_uniform()))
#데이터 컬럼이 13개였으므로 input_dim=13
model.add(layers.Activation('elu'))
model.add(layers.Dense(units=64, activation=None,
kernel_initializer=initializers.he_uniform()))
model.add(layers.Activation('elu'))
model.add(layers.Dense(units=32, activation=None,
kernel_initializer=initializers.he_uniform()))
model.add(layers.Activation('elu'))
model.add(layers.Dropout(rate=0.4)) #0.4만큼 드랍아웃
model.add(layers.Dense(units=1, activation=None)) #회귀일 때는 (출력)unit 1개
#모델 세팅(컴파일)
model.compile(optimizer=optimizers.Adam(), loss=losses.mean_squared_error,
metrics=[metrics.mean_squared_error]) #회귀이므로 MSE사용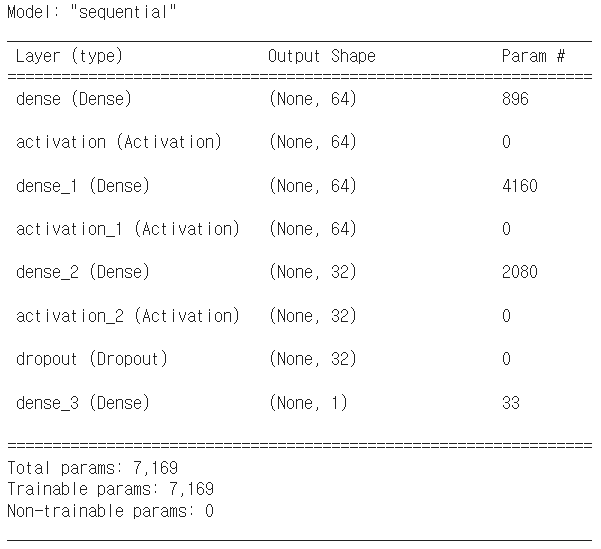
3. Train the model
history = model.fit(train_data, train_label, batch_size=100,
epochs=1000, validation_split=0.3, verbose=0)
#데이터 일부(0.3)를 validation으로 사용해 모델 학습 결과를 history에 저장4. Test the model
result = model.evaluate(test_data, test_label)
#test_X와 test_Y를 받아 evaluate실행: 보통 loss, test accuracy가 있음
#그러나 회귀의 경우 loss(=MSE)만 존재하므로 result[0]과 result[1] 둘 다 같은 값을 가짐
print("loss(MSE):", result[0]) #loss(MSE): 17.478260040283203+) history(0.7만큼 train, 0.3만큼 valid한 학습데이터)탐색
print(history.history.keys())
#dict_keys(['loss', 'mean_squared_error', 'val_loss', 'val_mean_squared_error'])
#각 학습별 loss, mse, val_loss, val_mse가 기록되어 있음
loss = history.history['mean_squared_error']
val_loss = history.history['val_mean_squared_error']
x_len = np.arange(len(loss))
plt.plot(x_len, loss, marker='.', c='blue', label='Train-set Acc.')
plt.plot(x_len, val_loss, marker='.', c='red', label='Validation-set Acc.')
plt.legend(loc='upper right'); plt.grid()
plt.xlabel('epoch'); plt.ylabel('loss(MSE)'); plt.show()
#train-set의 MSE와 valid-set의 MSE변화 시각화
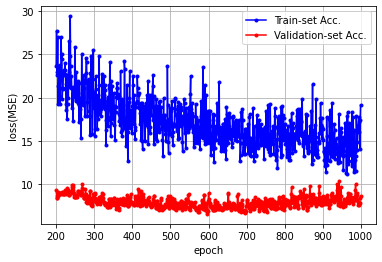
x_len = np.arange(len(loss))
plt.plot(x_len[200:], loss[200:], marker='.', c='blue', label='Train-set Acc.')
plt.plot(x_len[200:], val_loss[200:], marker='.', c='red', label='Validation-set Acc.')
plt.legend(loc='upper right'); plt.grid()
plt.xlabel('epoch'); plt.ylabel('loss(MSE)'); plt.show()
#200번째 x와 y의 데이터부터, MSE 변화에 대해 시각화 #결과는 오른쪽 위 그래프++) get_layer().weights

model.get_layer('dense_1').weights[0] #model의 dense_1 가중치 꺼내기
#값들을 numpy로 바꿔 shape탐색
a = model.get_layer('dense_1').weights[0].numpy().shape[0]
b = model.get_layer('dense_1').weights[0].numpy().shape[1]
a, b, a*b #(64, 64, 4096)
분야별 딥러닝 활용 사례
- Object Detection & Recognition: 컴퓨터 비전의 대표 적용 분야. 이미지 속 사물의 위치와 종류를 알아냄. CNN사용
*Convolutional Neural Network: Convolutional layer(feature extraction)와 Pooling layer 반복.
- ImageData Generator: 다양한 data augmentation (이미지를 기울이거나 줌을 주는 등으로 데이터 증강)적용 가능. `flow_from_directory()`를 활용해 이미지 데이터 폴더로부터 데이터를 가져와 training에 활용할 수도 있음.
- Image Segmentation: 원본 이미지와 object마다 pixel level에서 채색된 데이터(label)를 사용해 학습 진행. 결과를 사각형 영역으로 표현하는 Image Detection보다 더 디테일하게 대상 판별 가능
- Image Captioning: 이미지 추상화(CNN) -> 이미지 정보로 문장 작성(RNN). 이미지에서 (텍스트)정보 추출
- DCGAN(Deep Convolutional Generative Adversarial Network): 실제 존재하는 이미지로 학습 후 학습데이터에 존재하지 않는(가짜) 이미지 생성. Generator(생성자)와 Discriminator(식별자) 2개의 인공신경망을 함께 사용함. 생성자는 가짜 이미지를 만들어 식별자를 속이려 하고, 식별자는 이미지가 진짜인지 가짜인지 판별하기 위해서 학습하는 것. Style GAN, Info GAN, Stack GAN등 다양하게 활용됨
- 그 외에도 Visual Question Answering, Lip Reading Sentences in the Wild, TOEIC_BERT, KorBERT, Booksby.ai, GPT-2, Automatic Code Generator, DALL-E, DeepFakes, Xpression, Synthesia, Pose Detection & Pose Estimation 등 다양함
Convolutional Neural Network
- 합성곱 신경망. 합성곱 계층을 이용해 적은 가중치 수로 높은 성능의 이미지 분류 가능(이미지 내의 특징점을 잘 찾음)

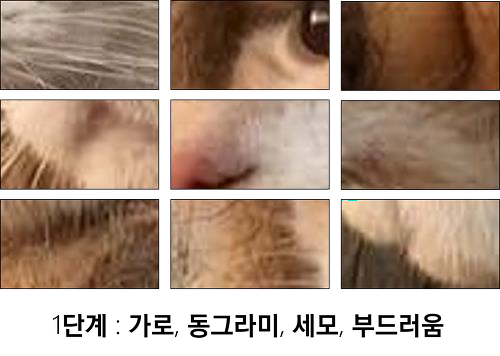


- 합성곱 계층을 쌓아나가면서 더 복잡하고 추상화된 정보를 추출함(1단계 -> 2단계 -> 3단계로 변화: 복잡한 정보로 발달)
- Convolution: 데이터 특징 추출 과정. 각 성분의 인접 성분들을 조사해 특징을 파악하고 그를 한 장(convolution layer)으로 압축. 이같은 과정을 수행하면서 파라미터 개수를 효과적으로 줄임:: 다양한 필터로 해당 패턴이 이미지에 있나 마킹(확인)
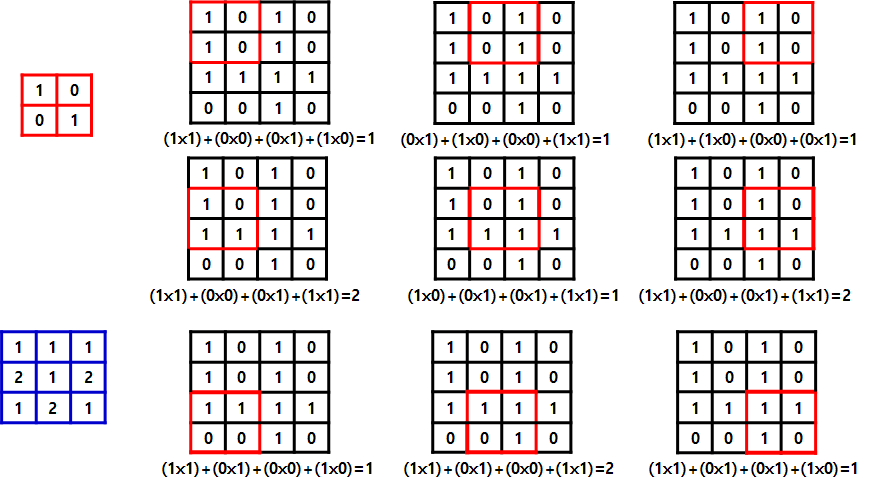
- 간단한 부품들로 더 복잡하고 멋진 부품을 (신경망이 알아서) 만듦
- 아래는 CNN 연습과정
#각종 임포트
import numpy as np; import pandas as pd
import matplotlib.pyplot as plt; import tensorflow as tf
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D
from tensorflow.keras.utils import to_categorical
from keras.preprocessing import image#간단한 CNN모델 생성
model = Sequential([
Conv2D(filters=32, kernel_size=(3, 3), activation='relu', input_shape=(28, 28, 1)),
MaxPooling2D((2, 2)),
Conv2D(64, (3, 3), activation='relu'),
MaxPooling2D((2, 2)),
Conv2D(64, (3, 3), activation='relu'),])
#Conv2D: 합성곱 계층. 마스크(커널/필터) 수, 마스크 크기(행, 열), input_shape에 (행, 열, 채널)
#CNN층(Conv2D)이 깊어질수록 필터 개수가 증가함을 알 수 있음(32 -> 64)
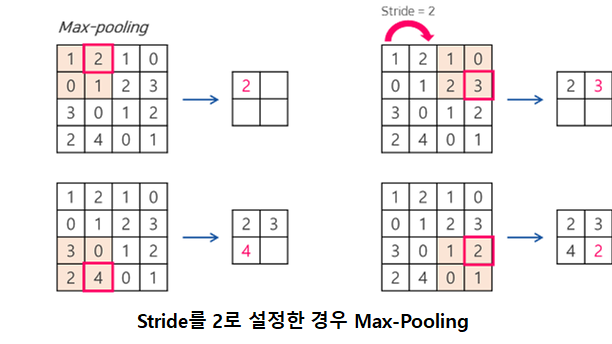
#MaxPooling2D: 풀링 계층. 가로세로 공간을 줄임. 윈도우 크기(행, 열)
#stride설정 시 윈도우 크기와 스트라이드는 같은 값으로 설정(윈도우가 3*3이면 스트라이드도 3)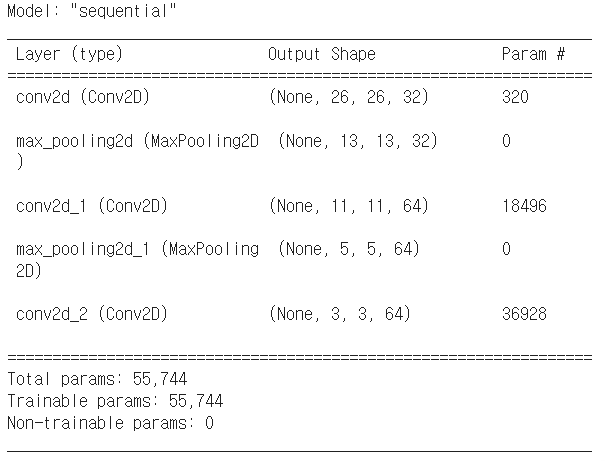
#위에서 만든 CNN에 분류기 추가하기
model.add(Flatten()) #(3, 3, 64)였던 걸 3*3*64인 576으로 만듦
model.add(Dense(64, activation='relu'))
model.add(Dense(10, activation='softmax'))
#만든 CNN모델에 MNIST 데이터 넣어보기
mnist = keras.datasets.mnist
(X_train, y_train), (X_test, y_test) = mnist.load_data()
print(X_train.shape, y_train.shape) #(60000, 28, 28) (60000,)
print(X_test.shape, y_test.shape) #(10000, 28, 28) (10000,)
#Convolution Layer와 MaxPooling이 2차원 데이터를 사용함: 데이터 변환
X_train = X_train.reshape((60000, 28, 28, 1)).astype('float32') / 255
X_test = X_test.reshape((10000, 28, 28, 1)).astype('float32') / 255
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
model.compile(optimizer='adam', loss=keras.losses.categorical_crossentropy,
metrics=['accuracy'])
history = model.fit(X_train, y_train, batch_size=64,
epochs=5, verbose=1, validation_split=0.2)
#에포크별 loss, accuracy, val_loss, val_accuracy를 알려줌(verbose=1)
print(model.evaluate(X_test, y_test)) #[0.0442, 0.9868] #순서대로 loss, accuracy
#위에서 Dense층을 사용했을 때(0.0595, 0.9821)보다 결과가 좋음
- Dense층은 입력 특성 공간 전체의 패턴을 학습하나, Convolution층은 지역 패턴(인근의 패턴)을 학습함
- CNN의 성질
1. 학습된 패턴은 평행 이동 불변성: Translation invariant. 적은 수의 훈련 데이터로도 일반화 능력을 가진 표현을 학습
2. 패턴의 공간적 계층구조 학습: 첫번째 합성곱 층이 edge같은 지역 패턴을 학습했다면 두번째 합성곱 층은 edge들로 구성된 더 큰 패턴을 학습하는 방식
- Feature map: 합성곱 연산에는 특성 맵이라 불리는 3D Tensor를 이용함. 2개의 공간축(높이, 너비)과 깊이축(채널)으로 구성. RGB이미지의 경우 컬러 채널이 3가지이므로 (높이, 너비, 3)
- padding: Convolution층을 지날때마다 크기가 줄어드는 문제를 해결하기 위해, 입력의 가장자리에 적절한 개수의 행과 열을 추가하는 것. 주로 Zero padding(테두리 부분을 0으로 채움)을 사용함.


- stride: 필터 적용 시, (필터가 이동할)간격을 조정하는 것. 위의 사진들은 모두 stride=1.
- MaxPooling: 특성 맵의 가중치 개수 감소를 위해 Downsampling하는 것. 평균보다 특성들의 최대값 사용이 더 유리하기 때문에 'MaxPooling'. (*특성 자체가 각 타일의 패턴이나 개념 존재 여부를 인코딩하는 경우가 많기 때문)
- Pooling: 처리할 데이터 크기를 줄이는 것. 위의 MaxPooling, 평균을 쓰는 AveragePooling, 릿지를 쓰는 L2normPooling등이 있음.
- CNN의 단점: MLP보다 많은 파라미터로 인해 메모리 용량이 큼, 많은 계산과정을 필요로 함, 실행시간이 느림
- 대표적인 CNN: LeNet(손글씨 숫자 인식), AlexNet(2012 이미지넷 이미지 인식대회(ILSVRC) 준우승), VGG16(2014 ILSVRC 준우승), GoogleNet(2014 ILSVRC 우승), ResNet(2015 ILSVRC 우승), SENet(2017 ILSVRC 우승)
'STUDY' 카테고리의 다른 글
| 파이썬 스터디 ver3. 15주차 (2) | 2022.10.29 |
|---|---|
| 파이썬 스터디 ver3. 14주차 (3) | 2022.10.22 |
| 파이썬 스터디 ver3. 12주차 (2) | 2022.10.10 |
| 파이썬 스터디 ver3. 11주차 (2) | 2022.10.03 |
| 파이썬 스터디 ver3. 10주차 (4) | 2022.09.19 |



