2022.09.12~2022.09.16
구름 X 전주 ict이노베이션 스퀘어의 온라인 코딩교육 내용을 정리하였습니다.
저 기간 동안의 강의에서는 앞에서 배운 딥러닝 기초(tensorflow v2), CNN위주의 실습들을 했습니다. 새로 알게 된 부분들 위주로 간단하게 정리하겠습니다.
Tensorboard
- callback으로 로그들을 넣을 폴더를 만들면, 그 로그들을 바탕으로 텐서보드에서 여러 지표와 그래프들을 보여줄 수 있당

Pycaret
- setup을 사용하면 알아서 train/test split, 간단한 전처리 등이 수행된다.! 이는 이후 모델생성 등에 train/test등을 쓰지 않아도 알아서 적용된다! 너무너무 신기..
from pycaret.classification import *
import pandas as pd; import numpy as np; import matplotlib.pyplot as plt
titanic_df = pd.read_csv("titanic_modified.csv")
model = setup(data=titanic_df, target='Survived', train_size=0.7, session_id=9)
#session_id는 random seed. 이렇게 몇몇 파라미터 값만 입력하면 된다!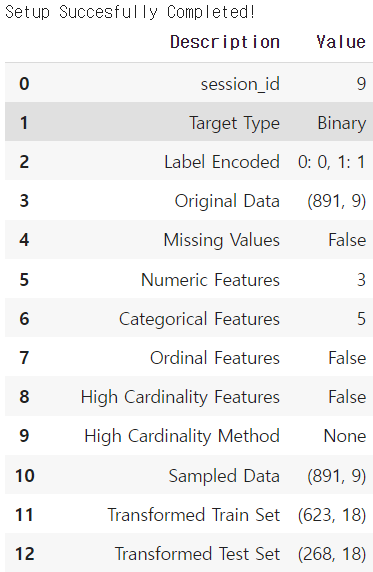
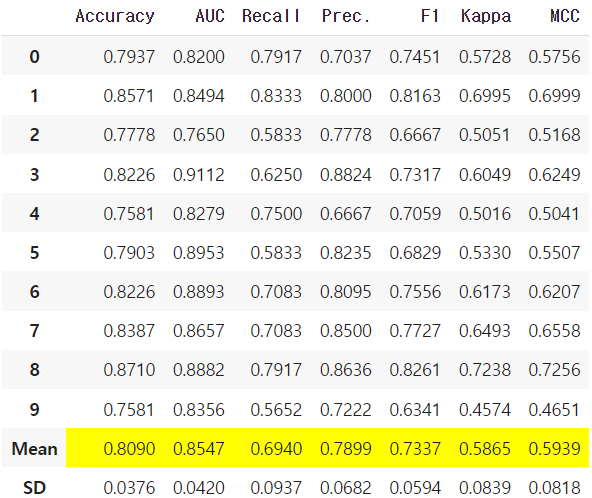
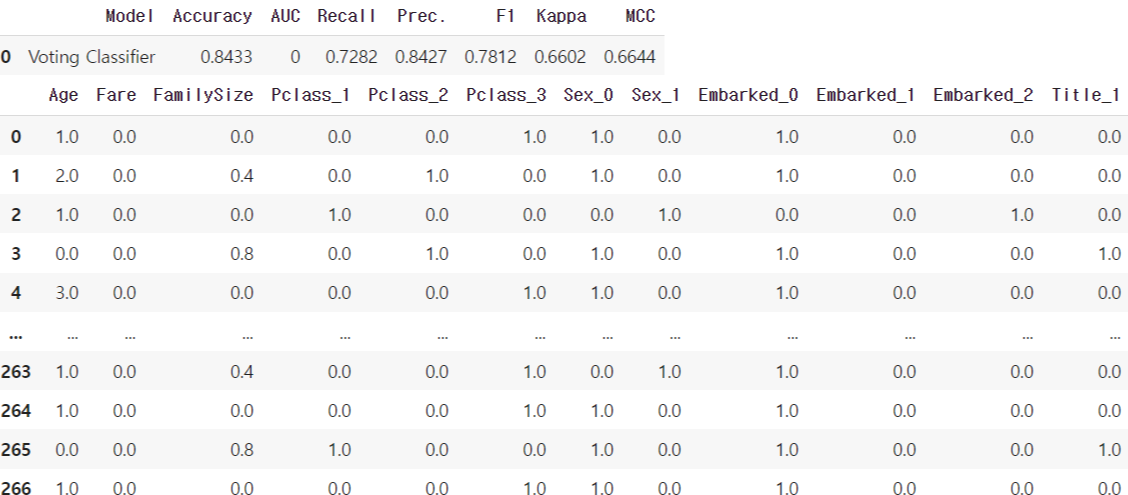
xgb = create_model('xgboost') #이렇게 모델만 만들어도 된다.!! #결과는 오른쪽 위에 첨부참고로 저 df 아래에는 하이퍼파라미터 정보들도 담겨있다. (base_score가 몇이고 booster로 뭐썼고 등등...)말 그대로 알아서 해준 것이다! 박수쫙쫙~!! 👏
xgb_tuned = tune_model(xgb, optimize='Accuracy')
#모델 하이퍼파라미터를 바꿔주는 친구라고 함. Accuracy기준 optimize!
그럼 이렇게 create_model 했을때와는 조금 다른 형태의 table을 만날 수 있다.
- 이 친구는 여러 모델 성능비교에 주로 쓰인다고 한다!
top_3_models = compare_models(sort='Accuracy', n_select = 3)
#저 sort기준이 될 수 있는 지표들로는 AUC, Recall, F1, Kappa등이 있따
#n_select는 그래서 sort기준으로 보았을 때 상위 몇개의 모델을 채택할 것이냐!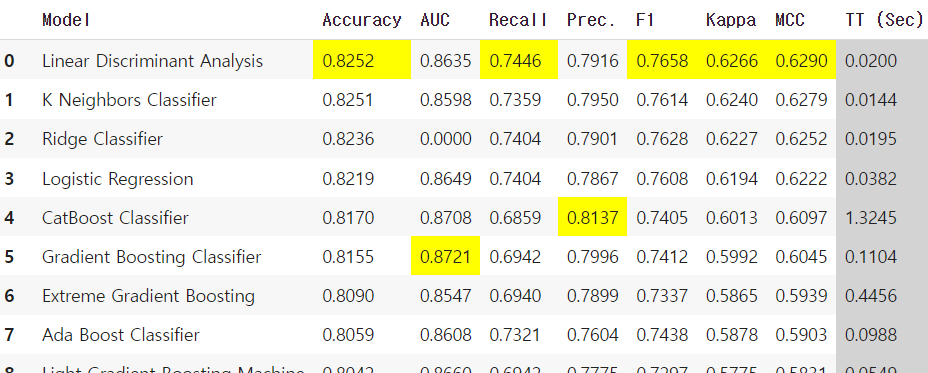
evaluate_model(top_3_models[0])
#top_3_models의 0번째 요소는 LDA(top_3_models에는 모델 3개가 리스트형태로 있음)
#설정된 하이퍼파라미터들, AUC, confusion matrix등을 볼 수 있따!
model_top = top_3_models[0]
plot_model(model_top, plot = 'auc')
#evaluate_model로 얻어지는 plot들 중 보고싶은 것만 지정해서 별도로 출력할 수도 있다
predict_model(top_3_models[0]) #test data에 대한 예측 결과값 보기
#Survived가 실제 y값, label이 예측값, score는 모델이 (예측)값에 대해 확신하는 정도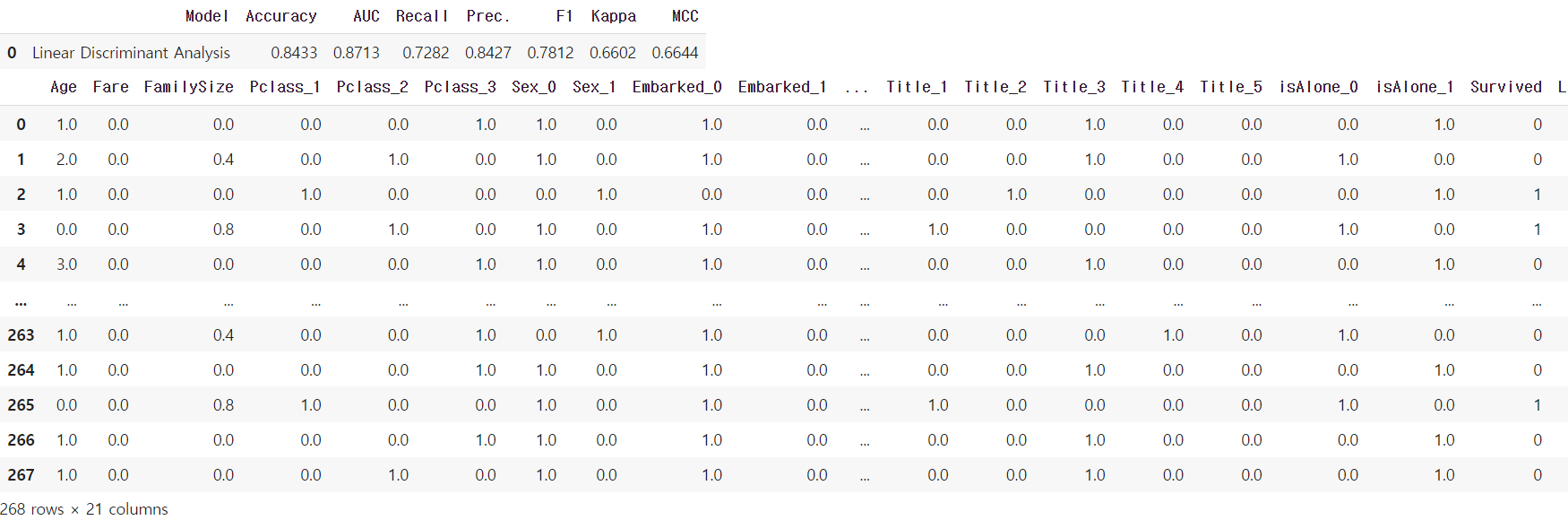
- 이렇게 고른 모델들을 blending하는 것도 가능하다
blended = blend_models(estimator_list=top_3_models, fold=10,
optimize='Accuracy', method = 'hard') #여기서 hard는 하드보팅
predict_model(blended) #위에서 blend해 만든 모델에 predict 수행
KerasTuner
- (딥러닝)수많은 하이퍼파라미터들의 최적조합을 찾을 때 사용
- (Bayesian Hyper Parameter Optimization:)파라미터가 hp인 함수를 넘겨받아 하이퍼파라미터 후보 결정(kt.BayesianOptimization 사용, 파라미터 max_trials로 시도할 총 trial수 설정)
- 어쨌든 kt로 찾은 하이퍼파라미터들을 모델에 적용해볼 수 있음... 사실 어려워서 반도 이해 못했다. 강의에서도 그냥 슉슉 이렇게 씁니다~!! 만 보여주고 말더라. 쩝
https://metamon-ditto.tistory.com/52
파이썬 스터디 ver3. 10주차
2022.08.22~2022.08.26 구름 X 전주 ict 이노베이션 스퀘어의 온라인 코딩교육 내용을 정리하였습니다. 이번에도 사실 저 기간은 아니지만 9주차(저번 글)에 이미 저번 프로젝트 관련 내용을 정리했었던
metamon-ditto.tistory.com
여기에서 했다가 개같이 멸망한 데이콘 청경채 대회... 그냥 두기엔 아쉬워서 1위 하신 분의 결과물을 보고 배우고자 합니다. 우선 이분과 저(희 팀)의 공통점과 차이점부터 짚고 넘어가자면.!!!
공통점: 식물대사 가정(input(data부분)의 18일 데이터들은 target의 19일 생장에 영향을 주었을 것), 파일 병합 및 취합, StandardScaler사용
차이점: 결측치 보간법을 사용하심, 컬럼들을 세세히 살펴보심(min과 max 살펴보고 컬럼 추가, 습도*온도 등의 컬럼 추가), XGboost 사용하심(저는 랜덤포레스트 사용), CV사용하심, 결론까지 내심, 저처럼 (분단위 -> 일단위)리샘플 안하심, 함수를 매우 적극적으로 사용하심!
https://dacon.io/competitions/official/235961/codeshare/6591
[private 1등] 6x2
청경채 성장 예측 AI 경진대회
dacon.io
아래는 설명과 이분의 코드를 따라 쳐보며 공부한 것들을 함께 주석 달아놓은 것입니다. 아주 쬐끔은 제가 수정한 부분도 있어요.
근데 진짜 신기하네요... 저는 하나하나 다 시도해보면서 잘 되면 냅두고 잘 안되면 지우는 방식으로 하면서 반복이 필요하다 생각한 부분(파일 불러오기 등)만 함수 썼는데 그냥 데이터 전처리 대부분에 함수 쓰신게.. 신기방기... 원래 다들 이렇게 하는 건가요...?
def change_year(date): #날짜 년도월일 형태로 변환
date = date[:10].replace("-","") #10번째자리까지만, -삭제
return date #2022-04-26 00:00:00이던 게 20220426이 됨#각종 컬럼들의 0(결측값)을 찾아내는 함수들
def filter_pump(x): #펌프작동남은시간 값이 0이 아닌 것만 남김
return x[x['펌프작동남은시간']!=0]
def filter_cold(x): #냉방작동남은시간 값이 0이 아닌 것만 남김
return x[x['냉방작동남은시간']!=0]
def filter_hot(x):
return x[x['난방작동남은시간']!=0]
def filter_inside_air(x):
return x[x['내부유동팬작동남은시간']!=0]
def filter_outside_air(x):
return x[x['외부환기팬작동남은시간']!=0]
def filter_white(x):
return x[x['화이트 LED작동남은시간']!=0]
def filter_blue(x):
return x[x['블루 LED작동남은시간']!=0]
def filter_red(x):
return x[x['레드 LED작동남은시간']!=0]
def filter_total_red(x):
return x[x['적색광추정광량']!=0]
def filter_total_blue(x):
return x[x['청색광추정광량']!=0]
def filter_total_white(x):
return x[x['백색광추정광량']!=0]
def is_in(type_list, type_dict, i):
try: #값이 존재한다면 type_list에 type_dict의 i번째값 append
type_list.append(type_dict[i])
except: #값이 존재하지 않는다면 type_list에 0 append
type_list.append(0)def change_col(particular_case):
particular_case['시간'] = particular_case['시간'].apply(change_year)
#받은 data(particular_case)의 '시간'컬럼에 change_year함수를 적용한 값을 덮어씌움
day_list = list(particular_case['시간'].drop_duplicates(keep='first'))
#particular_case의 '시간'컬럼의 중복을 첫번째를 남기고 지운 리스트를 day_list라 명명
##이러면 안그래도 날짜만 남은 particular_case 시간컬럼의 값 대부분이 사라지지 않나..??
group_df = particular_case.groupby('시간')
#particular_case의 '시간'값에 따라 groupby한 객체를 group_df라 명명
##시간(날짜)에 따라서 다른 컬럼값들을 보기 위함인가?
pump_list = []
group_pump = group_df.apply(filter_pump)
#group_df에 filter_pump함수를 적용(값이 있는 것들만 리턴)한 것을 group_pump라 명명
pump_dict = group_pump['시간'].value_counts().to_dict()
#group_pump의 시간 value_counts값들을 dict형태로 만들어 pump_dict라 명명
cold_list = []
group_cold = group_df.apply(filter_cold)
#group_df에 filter_cold함수를 적용한 것을 group_cold라 명명
cold_dict = group_cold['시간'].value_counts().to_dict()
#group_cold의 시간 value_counts값들을 dict형태로 만들어 cold_dict라 명명
hot_list = []
group_hot = group_df.apply(filter_hot)
hot_dict = group_hot['시간'].value_counts().to_dict()
inside_list = []
group_inside = group_df.apply(filter_inside_air)
inside_dict = group_inside['시간'].value_counts().to_dict()
outside_list = []
group_outside = group_df.apply(filter_outside_air)
outside_dict = group_outside['시간'].value_counts().to_dict()
white_list = []
group_white = group_df.apply(filter_white)
white_dict = group_white['시간'].value_counts().to_dict()
blue_list = []
group_blue = group_df.apply(filter_blue)
blue_dict = group_blue['시간'].value_counts().to_dict()
red_list = []
group_red = group_df.apply(filter_red)
red_dict = group_red['시간'].value_counts().to_dict()
total_red_list = []
group_total_red = group_df.apply(filter_total_red)
#group_df에 filter_total_red함수를 적용한 것을 group_total_red라 명명
group_total_red = group_total_red.reset_index(drop=True)
group_total_red = group_total_red.groupby('시간')
#인덱스 초기화+기존 인덱스 삭제, 시간에 따라 다시 groupby
total_red_dict = (group_total_red['적색광추정광량'].max() - group_total_red['적색광추정광량'].min()).dropna().to_dict()
#group_total_red의 적색광추정광량의 max에서 min을 뺀 값들을 dict형태로 만들어 total_red_dict라 명명
##max는 있는데 min은 없는 그런 경우를 막기 위해 dropna()를 쓰신건가???
max_red = []; min_red = []
max_red_dict = group_total_red['적색광추정광량'].max().to_dict()
min_red_dict = group_total_red['적색광추정광량'].min().to_dict()
#각각 group_total_red의 적색광추정광량 컬럼의 최대/최소값을 dict로 만든 것
total_blue_list = []
group_total_blue = group_df.apply(filter_total_blue)
group_total_blue = group_total_blue.reset_index(drop=True)
group_total_blue = group_total_blue.groupby('시간')
total_blue_dict = (group_total_blue['청색광추정광량'].max() - group_total_blue['청색광추정광량'].min()).dropna().to_dict()
max_blue = []; min_blue = []
max_blue_dict = group_total_blue['청색광추정광량'].max().to_dict()
min_blue_dict = group_total_blue['청색광추정광량'].min().to_dict()
total_white_list = []
group_total_white = group_df.apply(filter_total_white)
group_total_white = group_total_white.reset_index(drop=True)
group_total_white = group_total_white.groupby('시간')
total_white_dict = (group_total_white['백색광추정광량'].max() - group_total_white['백색광추정광량'].min()).dropna().to_dict()
max_white = []; min_white = []
max_white_dict = group_total_white['백색광추정광량'].max().to_dict()
min_white_dict = group_total_white['백색광추정광량'].min().to_dict()
sleep_list = []
sleep_time = particular_case[(particular_case['화이트 LED작동남은시간']==0) & (particular_case['레드 LED작동남은시간']==0) & (particular_case['블루 LED작동남은시간']==0)]
#화이트/블루/레드 LED작동남은시간이 모두 0인 경우를 sleep_time이라 명명
sleep_time = sleep_time.groupby('시간')
sleep_time = sleep_time.size().to_dict()
#이를 다시 시간으로 groupby한 뒤의 크기를 dict화하여 sleep_time에 저장
for i in day_list:
is_in(sleep_list, sleep_time, i)
#sleep_time의 i번째 값이 존재한다면 sleep_list에 i append, 없다면 0 append
is_in(pump_list, pump_dict, i)
is_in(cold_list, cold_dict, i)
is_in(hot_list, hot_dict, i)
is_in(inside_list, inside_dict, i)
is_in(outside_list, outside_dict, i)
is_in(white_list, white_dict, i)
is_in(blue_list, blue_dict, i)
is_in(red_list, red_dict, i)
is_in(total_red_list, total_red_dict, i)
is_in(total_blue_list, total_blue_dict, i)
is_in(total_white_list, total_white_dict, i)
is_in(max_red, max_red_dict, i)
is_in(min_red, min_red_dict, i)
is_in(max_blue, max_blue_dict, i)
is_in(min_blue, min_blue_dict, i)
is_in(max_white, max_white_dict, i)
is_in(min_white, min_white_dict, i)
new_group_df = group_df.mean() #group_df의 평균을 new_group_df로 저장
new_group_df['냉방 시간'] = cold_list #cold_list값을 냉방시간 컬럼값으로 설정
new_group_df['난방 시간'] = hot_list
new_group_df['내부 팬'] = inside_list
new_group_df['외부 팬'] = outside_list
new_group_df['백색'] = white_list
new_group_df['청색'] = blue_list
new_group_df['적색'] = red_list
new_group_df['LED_off'] = sleep_list
new_group_df['적색 크기차'] = total_red_list
new_group_df['청색 크기차'] = total_blue_list
new_group_df['백색 크기차'] = total_white_list
new_group_df['적색 최대'] = max_red
new_group_df['적색 최소'] = min_red
new_group_df['청색 최대'] = max_blue
new_group_df['청색 최소'] = min_blue
new_group_df['백색 최대'] = max_white
new_group_df['백색 최소'] = min_white
new_group_df['펌프 작동시간'] = pump_list
new_group_df['실내 일교차'] = list(group_df['내부온도관측치'].max() - group_df['내부온도관측치'].min())
#실내 일교차는 group_df의 내부온도관측치 컬럼의 max값-min값을 리스트로 묶은 값들
new_group_df['습도_온도'] = new_group_df['내부온도관측치'] * new_group_df['내부습도관측치']
#습도_온도는 new_group_df의 내부온도관측치 * 내부습도관측치
new_group_df['습도_온도_CO2'] = new_group_df['습도_온도'] * new_group_df['CO2관측치']
return new_group_df #함수 실행이 끝나면 new_group_df를 반환함def get_data(data_list):
copy_data_list = copy.deepcopy(data_list)
#인자로 받은 data_list를 deepcopy한 copy_data_list 생성
new_data = ""
for i in range(len(copy_data_list)): #range(10)은 0부터 9까지 해당
if i == 0:
new_data = copy_data_list[i]
#이 때 new_data는 copy_data_list의 0번째 요소가 됨
else:
new_data = pd.concat([new_data, copy_data_list[i]])
#new_data는 기존 new_data에 copy_data_list의 i번째 요소를 추가로 받음
del_list = []
for i in new_data.columns:
if '남은시간' in i:
del_list.append(i)
#만약 new_data의 컬럼들 중 '남은시간'이 포함된 컬럼이 있다면 del_list에 저장
new_data = new_data.drop(del_list, axis=1)
#new_data에서 del_list에 저장된 컬럼들을 드랍함
return new_datadef test_(df):
test_train = df.copy(deep=True)
#인자로 받은 df를 deepcopy한 test_train 생성
test_train['label'] = np.log1p(test_train['label'])
#test_train의 label컬럼에 log1p(로그)를 취해줌
y_train = test_train['label']
#로그취한 label값들을 y_train이라 명명
X = test_train.drop(['label'], axis=1)
#test_train에서 label컬럼만 드랍한 df를 X라 명명
X_col = X.columns
#X의 컬럼들을 따로 X_col이라 저장(왜 굳이..??)
scaler = StandardScaler()
scaler.fit(X) #표준화 스케일러 만들어서 적합
scaled_X_train = scaler.transform(X)
scaler_X_train = pd.DataFrame(scaled_X_train, columns=X_col)
#표준화시킨 값들을 df로 만듦(X_col말고 X.columns써도 될텐데..)
xg_reg = xgb.XGBRegressor(objective='reg:squarederror', max_depth=5)
#최대 깊이가 5인 xgbregressor 만들
nmse = cross_validate(xg_reg, scaled_X_train, y_train,
scoring=['neg_mean_squared_error'],
return_train_score=True, cv=5, n_jobs=-1)
#scaled_X_trian과 y_train데이터로 5번의 CV를 수행하는 과정에서 negMSE계산
##이경우 음수값 반환: 추후 양수로 출력하기 위해서는 -1을 곱해야 함(=MSE)
mse = -1 * nmse['test_neg_mean_squared_error']
rmse = np.sqrt(mse)
#-1을 곱해 MSE로 만든 뒤 sqrt를 씌워 rmse로 만듦
##처음부터 MSE로 구한 뒤 루트 씌워주는 게 낫지 않나..???
###cross_val_score, GridSearchCV등은 score출력 시 가장 높은 수치의
###score를 출력하기 때문에 결과값들의 순위를 바꿔주기 위해 neg를 붙인다고 함!!!
avg_rmse = round(np.mean(rmse), 4)
#rmse의 평균을 구함: 소수점 넷째자리에서 반올림
print("평균 RMSE:", avg_rmse)
return avg_rmsedef get_new_col(df, new_col):
cal_train = df.copy(deep=True)
for i in new_col:
split_col = i.split('*')
#new_col들 각각을 *기준으로 split
if len(split_col) >= 2:
col_name = ""
#만약 이렇게 나눈 split_col의 길이가 2개 이상이라면 col_name은 공백
for j in range(len(split_col)): #j는 0부터 split_col길이-1 까지
if j == 0:
col_name = split_col[j]
#j가 0이면 col_name은 split_col의 0번째 요소
cal_train['cal'] = cal_train[split_col[j]]
#cal_train에서 col_name을 찾은 값을 cal이라는 컬럼에 저장
else:
col_name += f'*{split_col[j]}'
#j가 0이 아니라면 col_name은 (직전)col_name * split_col의 j번째 요소
cal_train['cal'] *= cal_train[split_col[j]]
#cal_train에서 split_col의 j번째 요소값을 찾아 cal이라는 컬럼값에 곱함
df[col_name] = cal_train['cal']
#cal_train의 cal컬럼 값은 다시 df의 col_name이라는 컬럼 값으로 할당
##겁나 복잡해.. @-@ 새 컬럼을 이렇게 복잡하게 만들어야 하는건가...???
return df여기까지 각종 함수 정의, 이 아래부터 데이터 불러와서 함수 활용
train_list = []; col_list = []
for case in tqdm(range(1, 59)):
if case < 10:
case = '0'+str(case)
particular_case = pd.read_csv(f"/content/drive/MyDrive/opens/train_input/CASE_{case}.csv").interpolate()
##파일을 불러와 (선형으로 비례하는 방식으로) 결측치 보간: ts.interpolate()
group_ = change_col(particular_case)
group_ = group_.reset_index()
#보간한 particular_case에 change_col함수 실행, 인덱스 초기화한 걸 group_에 저장
particular_label = pd.read_csv(f"/content/drive/MyDrive/opens/train_target/CASE_{case}.csv").interpolate()
date_list = []
for date in particular_label['시간'].apply(change_year):
#particular_label에 change_year함수 적용 값들을 date라 칭함
date = datetime.strptime(str(date), '%Y%m%d')
before_day = date - timedelta(days=1)
#date의 형태를 바꾼 뒤 timedelta로 1일 전으로 만듦
date_list.append(before_day.strftime('%Y%m%d'))
#1일 전으로 돌린 str형 날짜를 date_list에 append
group_ = group_[group_['시간'].isin(date_list)]
group_ = group_.sort_values(by='시간')
#group_의 시간컬럼에 date_list값이 있는 것들만 인덱싱, 시간컬럼 값에 따라 sort
# if case == '1':
# col_list = group_.columns
# else:
# group_.columns = col_list
#case(파일순서?)가 1이면 col_list는 group_의 컬럼명들, 그렇지 않다면 반대(역)
##위의 코드 쓰려는데 계속 Length mismatch나서 주석처리하고 아래처럼 썼습니다..
col_list = group_.columns
group_['label'] = list(particular_label['rate'])
#particular_label의 rate컬럼값들을 리스트로 만든 뒤 group_의 label컬럼값으로 설정
growth_day = [j+1 for j in range(len(group_))]
group_['growth_day'] = growth_day
#group_의 길이만큼 반복하며 growth_day에 append한 리스트를 새 컬럼에 할당
if '외부온도관측치' in group_.columns:
group_ = group_.drop(['시간', '기준온도', '외부온도관측치', '외부습도관측치', '카메라상태'], axis=1)
else:
group_ = group_.drop(['시간', '기준온도', '외부온도추정관측치', '외부습도추정관측치', '카메라상태'], axis=1)
train_list.append(group_)
#만들었던 컬럼으로 대체되거나, 분석에 필요하지 않다 생각되는 컬럼들 드랍한 뒤 train_list에 append
##원래는 if문에 해당되는 코드만 있는데, 데이터를 직접 보면 데이터마다 컬럼명이 혼재되어 있습니다. 이에 if-else를 추가했어요!test_list = []; col_list = []
for case in tqdm(range(1, 7)):
case = '0'+str(case)
particular_case = pd.read_csv(f"/content/drive/MyDrive/opens/test_input/TEST_{case}.csv").interpolate()
group_ = change_col(particular_case)
group_ = group_.reset_index()
particular_label = pd.read_csv(f"/content/drive/MyDrive/opens/test_target/TEST_{case}.csv").interpolate()
date_list = []
for date in particular_label['시간'].apply(change_year):
date = datetime.strptime(str(date), '%Y%m%d')
before_day = date - timedelta(days=1)
date_list.append(before_day.strftime('%Y%m%d'))
group_ = group_[group_['시간'].isin(date_list)]
group_ = group_.sort_values(by='시간')
col_list = group_.columns
group_['label'] = list(particular_label['rate'])
growth_day = [j+1 for j in range(len(group_))]
group_['growth_day'] = growth_day
if '외부온도관측치' in group_.columns:
group_ = group_.drop(['시간', '기준온도', '외부온도관측치', '외부습도관측치', '카메라상태'], axis=1)
else:
group_ = group_.drop(['시간', '기준온도', '외부온도추정관측치', '외부습도추정관측치', '카메라상태'], axis=1)
test_list.append(group_)train = get_data(train_list)
test = get_data(test_list)
train.columns
test_(train) #test_는 xgbRegressor의 5CV 평균 rmse 리턴하는 함수 #평균 RMSE: 0.4819new_col = ['청색광추정광량*청색 크기차', '실내 일교차*growth_day',
'growth_day*EC관측치', '청색 최소*블루 LED동작강도', '외부 팬*난방 시간*적색 최소']
train = get_new_col(train, new_col)
test_(train) #컬럼들을 추가해서 다시 test_함수에 넣어봄 #평균 RMSE: 0.4375새 컬럼들을 만들어(여러 컬럼들 간의 곱을 추가하는 식)가다가.. RMSE가 가장 적은 마지막을 채택하게 되는데, 아래와 같습니다.
total_new_col = ['청색광추정광량*청색 크기차', '실내 일교차*growth_day',
'growth_day*EC관측치', '청색 최소*블루 LED동작강도',
'외부 팬*난방 시간*적색 최소', '화이트 LED상태*최근분무량',
'최근분무량*냉방부하', '레드 LED동작강도*growth_day*EC관측치',
'청색 최소*블루 LED동작강도*냉방부하', '펌프상태*적색광추정광량',
'습도_온도*실내 일교차*growth_day','펌프상태*실내 일교차*growth_day',
'냉방 시간*습도_온도','펌프상태*청색 최소*블루 LED동작강도*냉방부하',
'백색 크기차*외부 팬*난방 시간*적색 최소',
'펌프상태*청색 최소*블루 LED동작강도*냉방부하*블루 LED상태']
train = get_new_col(train, total_new_col)
test_(train) #평균 RMSE: 0.3611train = get_data(train_list)
test = get_data(test_list)
train = get_new_col(train, total_new_col)
#RMSE가 제일 적었던 (추가)컬럼들로 설정
test = get_new_col(test, total_new_col)
#train과 test에 똑같이 total_new_col의 컬럼들을 추가해 줌train['label'] = np.log1p(train['label'])
#train data의 label값에 log
y_train = train['label']
X = train.drop(['label'], axis=1)
X_test = test.drop(['label'], axis=1)
#train의 label값을 y_train으로 넘긴 뒤 X의 train/test에서 label컬럼 삭제
X_col = X.columns
scaler = StandardScaler()
scaler.fit(X)
scaled_X_train = scaler.transform(X)
scaled_X_train = pd.DataFrame(scaled_X_train, columns=X_col)
scaled_X_test = scaler.transform(X_test)
scaled_X_test = pd.DataFrame(scaled_X_test, columns=X_col)
#X의 train/test데이터들을 표준화 scaler만들어 적용한 뒤 Dataframe으로 만듦
scaled_X_test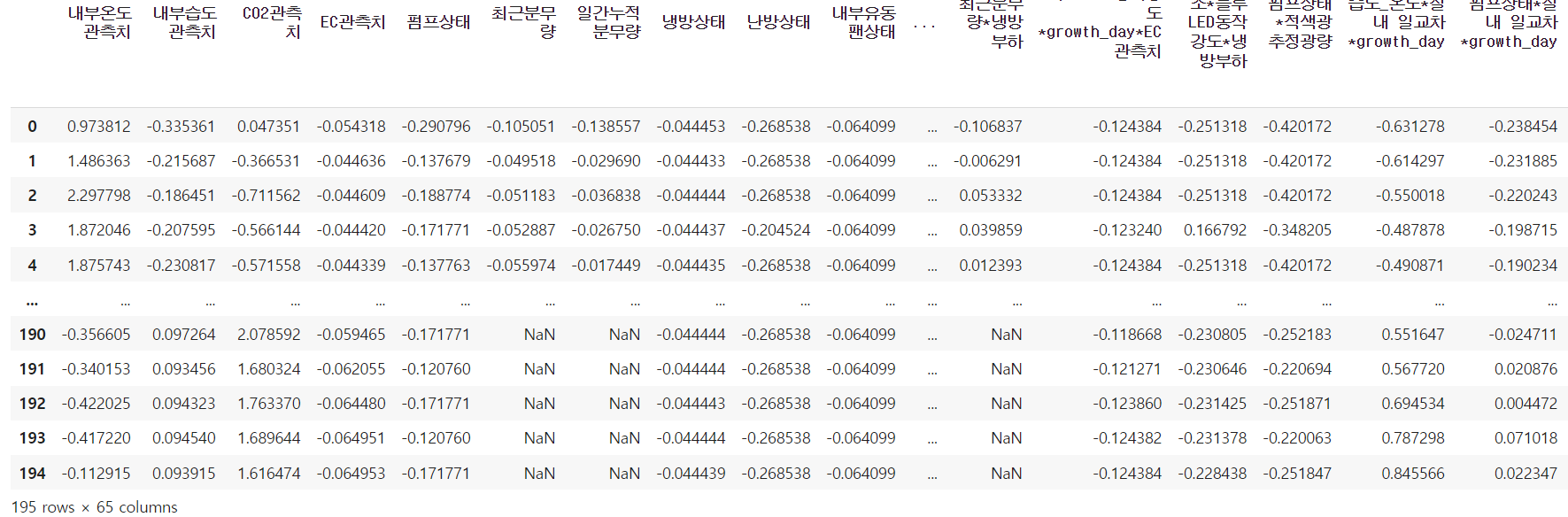
xg_reg = xgb.XGBRegressor(objective='reg:squarederror', max_depth=5)
xg_reg.fit(scaled_X_train, y_train)
#최대 깊이가 5인 XGB회귀모델을 만들어 scaled_X_train, y_train 적합
pred = xg_reg.predict(scaled_X_test)
#scaled_X_test에 대해 예측한 값들을 pred에 저장
result = []
for k in pred:
result = np.hstack([result, k])
#pred값들을 result리스트에 하나씩 쌓음
result
expm1_result = np.expm1(result) #exp(result) - 1
##앞에서 log1p했었으니까 반대로 expm1 해주는듯하다!
expm1_result = pd.DataFrame(columns=['label'], data=expm1_result)
total_result = []
for case in tqdm(range(1, 7)):
case = '0' + str(case)
particular_label = pd.read_csv(f'/content/drive/MyDrive/opens/test_target/TEST_{case}.csv')
particular_label['rate'] = list(expm1_result['label'][:len(particular_label)].values)
expm1_result = expm1_result.drop([i for i in range(len(particular_label))])
expm1_result = expm1_result.reset_index(drop=True)
total_result.append(particular_label)
for i in range(len(total_result)):
total_result[i].to_csv(f"TEST_0{i+1}.csv", index=False)
#total_result의 값들을 하나씩 csv로 저장해주고
file_ls = ['TEST_01.csv','TEST_02.csv', 'TEST_03.csv', 'TEST_04.csv', 'TEST_05.csv', 'TEST_06.csv']
with zipfile.ZipFile("submission.zip", 'w') as my_zip:
for i in file_ls:
my_zip.write(i) #압축!~!!
my_zip.close()위에서 함수 정의한 부분을 따라칠때는 "아 이런 기능을 쓰셨구나"말고는 왜 이렇게 복잡하게 하지..? 아니 애초에 이렇게 하는 게 맞나? 뭐지??? 하며 오히려 의아함 MAX였습니다. 근데 아래에서 train / test 데이터 개수만큼 for문을 돌리면서 안에서 함수를 적용하신 거 보고.. 우와 했어요. 아마 하나씩 해보셨다가 반복되는 작업들을 모두 함수로 재정의해주신 거겠죠..??
'STUDY' 카테고리의 다른 글
| 파이썬 스터디 ver3. 16주차 (3) | 2022.11.16 |
|---|---|
| 파이썬 스터디 ver3. 15주차 (2) | 2022.10.29 |
| 파이썬 스터디 ver3. 13주차 (0) | 2022.10.19 |
| 파이썬 스터디 ver3. 12주차 (2) | 2022.10.10 |
| 파이썬 스터디 ver3. 11주차 (2) | 2022.10.03 |



