제이림에서 하던 금융 프로젝트가 끝나, 기존의 5번을 기획 및 기타 비즈니스 관련 지식으로 정리하고자 합니다.
이로써 형태는 개략적으로 (1) 데이터 (2) 개인 프로젝트 (3) 알고리즘 (4) IT, CS (5) 비즈니스 (6) 콘텐츠/마케팅으로 설정되었습니다..
/ 3월 말~4월 초, 네오플의 공채가 있다는 소식을 알았습니다. 데이터분석 직군도 있었던 만큼.. 열심히 준비해서 잘 트라이 해보겠습니다.!! 그런 고로 넥슨 / 네오플 둘 다 ML / 수학 / 통계에 대한 기본적 이해를 필요로 하던 만큼 수학공부를 제대로 해야겠어요! // 7번으로 ML / 수학 / 통계를 추가할까 아니면 그냥 혼자 공부하는 것에서 끝낼까 생각중입니다.
1.
https://www.intelligencelabs.tech/d6ebf8d9-db34-42af-a7a5-4bf58d25670f
개인화 배너 지식으로 본 NPTI 개인화배너 사례
Table of contents
www.intelligencelabs.tech
https://www.intelligencelabs.tech/7430a289-22e5-4967-b3b8-03a8644b189f
LTV (LifeTime Value) 지표 속 BG/NBD 모델과 Gamma-Gamma 모델 파헤치기
Table of contents
www.intelligencelabs.tech
2. 개인프로젝트
여전히 과적합과 싸우는 중. (1)특정 컬럼을 없애고 (l2규제를 적용한) 로지스틱 회귀를 돌려보고 (2)StandardScaler를 사용해도 보고 (3)다른 모델을 사용해보기도 하고(LightGBM, 랜덤포레스트)...
- 어떻게 해야 이 과적합을 풀 수 있을까. '데이터 과적합 해결'이라고 구글링하면 데이터 증강이나 규제 같은 것들이 나오는데 규제도 다 써봤고, 데이터 증강은... 정형 데이터 특성 상 힘들지 않을까. 데이터 크기를 더 키워야 하는건가..? 아니면 전처리를 다시 해보아야 하나?? ㅠㅠㅠ



- 라고 포기하려던 찰나, 생각해보니 규제를 모델 안에서만 사용해왔던 걸 깨닫고 Lasso와 Ridge를 직접 사용해 보았다. 그리고..!!!! 릿지에서 유의미한 정확도 하락을! 처음으로! 경험했다ㅠㅠ 너무 감동...
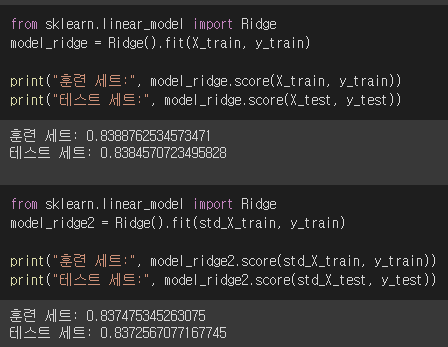

- 릿지는 모든 원소를 0이나 0에 가깝게 만들고(Bias증가 Variance감소), 랏소는 일부 원소를 0으로 만든다: 보통 유의미한 변수가 적을 땐 랏소, 유의미한 변수가 많을 땐 릿지를 쓴다고 한다. 내 데이터 케이스의 경우 train / test 스플릿 전, 더미변수화 -> 여러 트리모델 구현하며 '변수 중요도'가 높은 것들만 취사선택하였기 때문에 릿지를 쓰는 게 적합한 것 같다.
- Standard Scaler를 사용 하는 것과 하지 않는 것의 정확도가 거의 일치한다면(소수점 다섯째자리 이하 정도의 차이만 있다면) 굳이 사용하지 않아도 되는 것 아닐까? => 결론: 그냥 train/test데이터 그대로 사용하자!
- 근데... 릿지는 선형 회귀모델 기반이다. 난 분류를 하고싶었는데..!!!? 흠... 릿지 이후 분류모델을 사용할까?
- 일단 서포트벡터 분류기를 사용해봤는데... train+test 다 하면 데이터가 약 십만 개라, 실행에만도 엄청난 시간이 걸렸고 정확도 면에서도 만족스럽지 않았다. 규제를 나름 빡세게 줘서(C=0.001)그런가?:: train데이터 기준 정확도는 선형 분리에서 0.999, 비선형 분리에서 0.947
3. 유니온 파인드(Union-Find): https://cafe.naver.com/dremdeveloper/3
[알고리즘]Union & Find(disjoint set)
대한민국 모임의 시작, 네이버 카페
cafe.naver.com
https://c4u-rdav.tistory.com/44
[파이썬으로 배우는 알고리즘] Union-Find 알고리즘
Union-Find의 개념 Union-Find 알고리즘을 알기 위해서는 Disjoint Set의 개념부터 알고 가야 합니다. Disjoint Set이란? Disjoint Set이란 상호배타적인 집합으로 서로 중복되지 않는 부분 집합들로 나눠진 원소
c4u-rdav.tistory.com
상호 배타적(disjoint)인 분리형 집합 데이터 구조. 각 집합 데이터 구조 간 공통 원소가 없음
- Union: 두 집합을 하나의 집합으로 합침 / Find: 어떤 원소 x를 받았을 때 x가 속한 집합 반환
- disjoint set: 연결된 노드끼리를 그룹으로 묶어 연결 여부를 효율적으로 파악할 수 있게 함.
- 각 집합의 root(대표값)을 정하고 데이터 배열로 표현 -> 보통 root는 집합의 제일 작은 값, 같은 root를 가진 원소는 모두 같은 집합이라 가정
- 원본 값과 루트를 배열로 나타내고, 배열의 인덱스가 가진 값이 됨. 처음엔 자신들의 원본 값을 root로 갖고 있다가, 적은 값을 루트로 가지도록 수정됨(집합 (1, 7)의 루트값은 각각 1, 1이고 집합 (2, 5)의 루트값은 각각 2, 2가 됨)
4. 구글 바드와 챗 지피티: https://yozm.wishket.com/magazine/detail/1893/
구글AI '바드' 공개, SEO의 위기일까? | 요즘IT
ChatGPT의 영향은 기술 업계 전반에 걸쳐 느껴졌고, 구글은 이 AI 채팅 도구의 인기에 발 빠르게 대응해야 했습니다. ChatGPT와 같은 도구의 기능과 잠재력을 인식한 구글은 이 인기 있는 AI 채팅 도
yozm.wishket.com
https://yozm.wishket.com/magazine/detail/1897/
구글 바드 vs ChatGPT, 관전 포인트 3가지 | 요즘IT
지난 2월 8일, 구글 이벤트가 있었다. 핵심은 구글의 대화형 AI '바드(Bard)'를 소개하는 자리였다. 바드의 기본 기능, 사용 엔진, 앞으로의 가능성을 엿볼 수 있었다. 원래라면 바드를 보고 전
yozm.wishket.com
https://stibee.com/api/v1.0/emails/share/qa_hs9BTw4xaSCazbVgvKXESyqZ6N-w=
☕️ 새로운 검색 엔진 경쟁의 서막
1. 늦기 전에 움직이는 구글, 2. IRA가 계획했던대로, 3. 블룸버그 오리지널
stibee.com
오픈AI의 챗 지피티ChatGPT, 구글의 바드Bard
- 바드, 사용자의 검색어에 대한 맞춤 답변 + 추가 인사이트(검색 결과 페이지의 기사, 동영상 등): 사용자의 검색 맥락과 의도 파악해 개인화된 결과 제공 -> 사용자 친화적인 검색 가능
- 챗 지피티는 마이크로소프트의 빙에 도입되고, 바드는 구글에 도입됨. 구현 방식은 둘 다 비슷(AI생성 답안 + 기존 결과)
- SEO전략 조정방법 1)콘텐츠 제작에 AI 남용하지 않기 2)사실에 입각한 고품질 콘텐츠 제작 3)정기적인 콘텐츠 업데이트 4)사용자 참여 이끌어내기, 커뮤니티 관리
- 현재와 비슷한 검색엔진 형태는 유지될 것이나 아직은 ChatGPT의 확장성이 더 좋음(엣지에 탑재): 제대로 적용된 이후엔?
- 대화형 생성 AI 기반 검색은 기존 검색보다 비용이 많이 듦: 문제는 비용구조
+) 유닷컴: https://yozm.wishket.com/magazine/detail/1885/
구글에 도전장 내민 AI 검색엔진, 'You.com' | 요즘IT
검색엔진의 대명사는 구글이다. 그러나 검색엔진이 구글만 있는 것은 아니다. 이번 글에서 소개할 You.com도 검색엔진이다. 2021년 11월부터 공개 베타를 진행 중이고, AI를 활용한 개인화에 초점을
yozm.wishket.com
- 정확도 등이 아쉽긴 하지만 정보 가공, 정리, 필터링 기능 제공
5. User eXperience: https://yozm.wishket.com/magazine/detail/1887/
사용자를 화나게 만드는 ‘UX 라이팅’의 함정 | 요즘IT
누구나 한 번쯤 서비스나 멤버십을 해지해 본 경험이 있을 텐데요. 이때 간편했던 가입 절차에 비해, 해지 절차는 여러 단계를 거쳐야 해서 불편할 때가 있습니다. 혜택을 강조하며 가입을 유도
yozm.wishket.com
사용자를 화나게 하는 것: 다크패턴 디자인(사용자 기만장치를 숨겨 자신들이 원하는 행동 유도), 컨펌 쉐이밍(사용자가 부정적인 감정을 느끼게 만드는 문구)
소비자 여정의 새로운 해석, 메시 미들 이론 | 고구마팜
디지털 시대에서 살아남고 싶은 마케터는 필독
gogumafarm.kr
메시 미들 이론: 소비자의 구매 결정 과정은 일방향적이지 않고 탐색과 평가의 과정이 복잡하게 얽혀있다는 것
- 노출과 구매 유발 단계에서 SNS를 활용 / 소비자가 정보를 접하는 접점 확인(유튜브, 각종 SNS 콘텐츠)
브랜드 뉴스룸 사례로 이해하기 | 고구마팜
짧은 영상이 인기인 시대에 왜 텍스트 위주인 뉴스룸을 운영할까?
gogumafarm.kr
브랜드 뉴스룸: 브랜드와 관련된 최신 정보를 브랜드의 목소리로 들을 수 있는 곳
- 브랜드 뉴스, ESG(Environment, Social, (corporate)Governance), 조직문화, 이슈 매니지먼트 네 파트로 나뉨
- 목적(소비자 / 기사화 / 등)에 따라 브랜드 보이스를 맞추어 작성해야 함
'STUDY' 카테고리의 다른 글
| 취준로그 ver0.9 (1) | 2023.03.17 |
|---|---|
| 패스트캠퍼스 데이터분석 부트캠프 학습일지4 (1) | 2023.03.17 |
| 패스트캠퍼스 데이터분석 부트캠프 학습일지3 (4) | 2023.03.10 |
| 취준로그 ver0.7 (1) | 2023.03.03 |
| 패스트캠퍼스 데이터분석 부트캠프 학습일지2 (0) | 2023.03.02 |



