과제의 늪에서 허우적댄 한 주(3.28~4.1)였습니다. 저번주 한주동안만 과제 5개를 받았어요! 금토일동안 대부분 쳐내긴 했는데.. 글을 쓰고 있는 시점인 월~화에도 아직 하나 남았습니다. ^^와 신난다!
쉽지 않네요.
https://www.acmicpc.net/problem/2609
2609번: 최대공약수와 최소공배수
첫째 줄에는 입력으로 주어진 두 수의 최대공약수를, 둘째 줄에는 입력으로 주어진 두 수의 최소 공배수를 출력한다.
www.acmicpc.net
import math; import sys
a, b = map(int, sys.stdin.readline().split())
print(math.gcd(a, b))
print(math.lcm(a, b))두 개의 자연수를 입력받아 최대 공약수와 최소 공배수를 출력하는 프로그램을 작성하시오.
> 이거 뭐야.. 몰라.. 무서워... 최대공약수 최대공배수 개념이 생각안나서 네이버에 검색도 해보고 나름 알고리즘도 짜봤는데 번번히 실패해서 그냥 구글링했더니 이렇게 푸셨더라. 이거 아니면 백준 알고리즘 분류의 '유클리드 호제법'을 쓴다고.
> 호제법: 두 수가 서로 상대방 수를 나누어서 원하는 수를 얻는 알고리즘. 두 자연수 a, b에 대해(a>b) a를 b로 나눈 나머지가 r이라 하면 a와 b의 최대공약수는 b와 r의 최대공약수와 같다는 것. 이에 b를 r로 나눈 나머지 r`를 구하고 다시 r을 r`으로 나눈 나머지를 구하다 나머지가 0이 될 때 나누는 수가 a와 b의 최대공약수. 최소공배수는 a와 b의 곱을 a와 b의 최대공약수로 나누면 나옴.
def LCM(a, b):
while b > 0:
a, b = b, a % b
return a #최대공약수
def GCF(a, b):
return a * b / LCM(a, b) #최소공배수> 아래는 참조한 블로그 주소. 블로그 글 내의 링크를 타고 가면 유클리드 호제법에 대한 설명도 있다..!
https://velog.io/@junyp1/백준-2609-Python-최대공약수와-최소공배수
백준 - 2609 (Python) - 최대공약수와 최소공배수
백준 2869 최대공약수와 최소공배수 앞서 포스팅했던 []**
velog.io
> 언젠가.. 다시 풀긴 해야겠다
https://www.acmicpc.net/problem/11866
11866번: 요세푸스 문제 0
첫째 줄에 N과 K가 빈 칸을 사이에 두고 순서대로 주어진다. (1 ≤ K ≤ N ≤ 1,000)
www.acmicpc.net
import sys
n, k = map(int, sys.stdin.readline().split())
people = [i for i in range(1, n+1)]
answer = []
idx = 0
while people:
idx += k-1
if idx >= len(people):
idx %= len(people)
answer.append(people[idx])
people.pop(idx)
print("<"+", ".join(map(str, answer))+">")1번부터 N번까지 N명의 사람이 원을 이루면서 앉아있고, 양의 정수 K(≤ N)가 주어진다. 이제 순서대로 K번째 사람을 제거한다. 원에서 사람들이 제거되는 순서를 (N, K)-요세푸스 순열이라고 한다. 요세푸스 순열 출력.
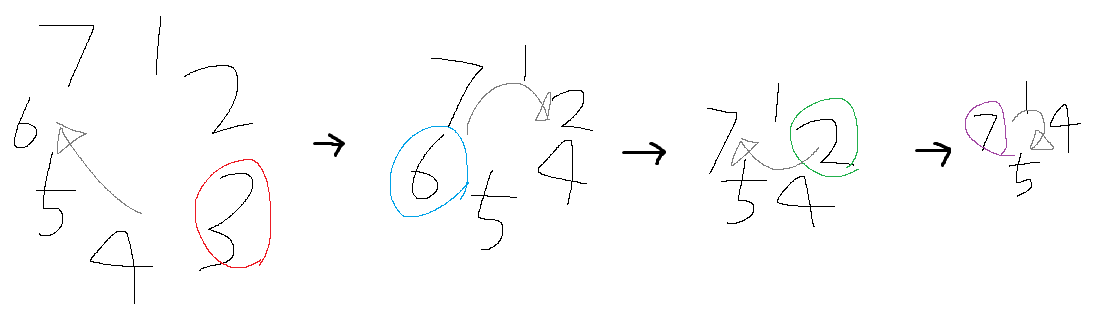
> 요세푸스 순열이란 걸 첨 들어봐서 이해하기 위해서 그림을 그렸습니다. 어떻게 K번째 사람을 제거하는데 3다음 6이지? 했다가(3이 나가면 [1, 2, 4, 5, 6, 7]일 텐데 여기서 3번째 원소는 4가 아닌가?) 그림을 그려보고 나서야 그 순서가 '제거된 사람 기준'인 걸 깨달았어요.
> 자 개념은 이해했는데 이걸 어떻게 구현하죠? ㅋ..ㅋㅋㅋ...
> 일단 알고리즘 분류에 '큐'가 포함되어 있길래 큐에 대해서도 찾아봤습니다.
https://mong9data.tistory.com/36?category=885885
[자료구조][파이썬/Python] 큐(Queue)
큐(Queue) 큐(Queue)는 데이터 값을 저장하는 기본적인 구조로, 일차원의 선형 자료구조이다. 기본적으로 값을 저장하는 연산 enqueue와 저장된 값을 꺼내는 연산 dequeue가 제공되어야 한다. 부가적으
mong9data.tistory.com
https://www.daleseo.com/python-queue/
파이썬에서 큐(queue) 자료 구조 사용하기
Engineering Blog by Dale Seo
www.daleseo.com
큐: 데이터 값을 저장하는 기본적인 구조로, 일차원의 선형 자료구조. 값을 저장하는 연산 enqueue와 저장한 값을 꺼내는 연산 dequeue가 제공되어야 함. 스택과 마찬가지로 FIFO(First In First Out, 선입선출)를 따름.
- 사용방법: 리스트(pop(n), insert(0, n) 사용), deque(collections모듈), Queue(queue모듈)
> 음..! 봐도 모르겠어요. 구글링 했습니다. 근데 다들 deque를 쓰시더라구요..? 저는 리스트로 풀고싶었는데.. 그러다 겨우겨우 찾아냄. 이분 코드를 뜯어보고 제 방식으로 조오금 바꿨습니당.
https://zoozoozoo.tistory.com/272
[백준] 11866번 요세푸스 문제 0 - 파이썬
https://www.acmicpc.net/problem/11866 11866번: 요세푸스 문제 0 첫째 줄에 N과 K가 빈 칸을 사이에 두고 순서대로 주어진다. (1 ≤ K ≤ N ≤ 1,000) www.acmicpc.net n, k= map(int,input().split()) people..
zoozoozoo.tistory.com
데이터분석<ver0.5>: K-드라마 프로그램, 출연진, 채널, 시청률 등의 TV 콘텐츠 DB 데이터
- 저번주엔 `분석에 방해되리라 생각되는 컬럼 4개 drop`, `PROGRM_BEGIN_TIME 컬럼 값 살펴보기` 까지 했다.
이제 남은 칼럼은 24개이며, 아래와 같다.
저번주, `PROGRM_BEGIN_TIME` 의 실제 값이 0이며 이는 자정에 시작한다는 뜻이란 걸 알았다.
이에 혹시나 모를 오류를 방지하기 위해서..! 프로그램 시작시간과 종료시간에 1초씩 시간을 더해주려 한다.. 그러나 그전에, 혹시나 `PROGRM_BEGIN_TIME` 혹은 `PROGRM_END_TIME`값이 59로 끝나는 것이 없진 않은지 먼저 확인해 추가적으로 손을 봐야 할 것이다. 그렇지 않으면 60초가 생겨나 추후 분석에서 정확하지 않고 이상한 값을 도출할 수 있기 때문ㅠ
data = data.astype({'PROGRM_BEGIN_TIME':'str', 'PROGRM_END_TIME':'str'})
data.dtypes #우선 인덱싱해 값 찾기 편하게 문자열로 바꾸자
성공적으로 바뀌었다! 이제 시작시간이나 끝시간이 59초로 끝나는 것들을 찾아보자.
conds = data[(data['PROGRM_BEGIN_TIME'].str.endswith('59')) | (data['PROGRM_END_TIME'].str.endswith('59'))]
conds #str.endswith()는 ()로 끝나는 것들을 찾아준다! #or로 두 조건 중 하나라도 만족하면 찾도록 만든다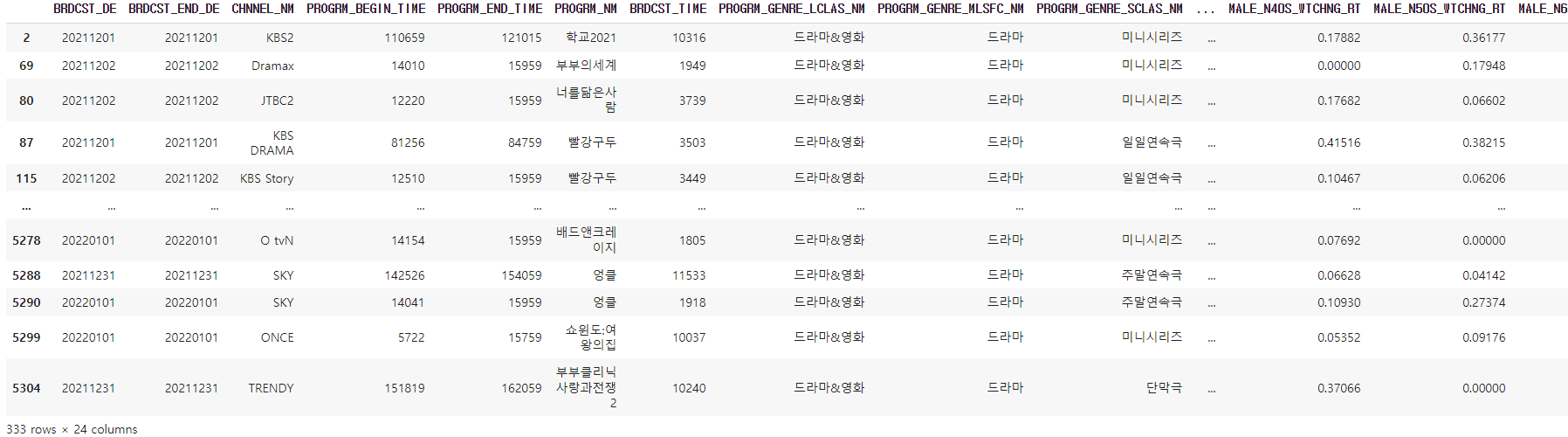
잘 찾아 진 것 같다. 데이터가 무려 333개나 된다..!
이런..식으로 하려다가 그냥 포기했다. str.endswith()를 알아본 김에 str.replace()를 쓰고싶어졌고 그를 위해 정규표현식을 검색해보다.. 현타가 왔기 때문이다. 그냥 0으로 둘걸 왜 괜히 쓸데없이 처리해야 한다고 생각해서… ㅂㄷㅂㄷ
년/월/일 구분, 작품명별 구분, 작품 대분류/중분류/소분류별 구분, 방영시간따라(30분 미만 / 30분 이상 1시간 미만 / 1시간 이상) 구분, 나이대별 선호도 구분, 성별별 선호도 구분 등으로.. 어떻게 나눠 구할것인지에 대해 더 고민하는 게 나을 것 같다.. ㅎ 중간고사가 끝난 이후부터 제대로 착수할 수 있도록 해야겠다.
'STUDY' 카테고리의 다른 글
| 파이썬 스터디 ver2. 4주차 (0) | 2022.05.12 |
|---|---|
| 파이썬 스터디 ver2. 3주차 (1) | 2022.05.08 |
| 파이썬 스터디 ver2. 1주차 (3) | 2022.03.31 |
| 파이썬 스터디 10주차 (3) | 2022.03.18 |
| 파이썬 스터디 9주차 (0) | 2022.03.04 |


