뭐했다고 시간이 이렇게 흘렀을까~~요.
분명 휴강도 많이했는데 그만큼 과제도 많고 쌓인것도 많아서 행복한 한주입니다
https://www.acmicpc.net/problem/1978
1978번: 소수 찾기
첫 줄에 수의 개수 N이 주어진다. N은 100이하이다. 다음으로 N개의 수가 주어지는데 수는 1,000 이하의 자연수이다.
www.acmicpc.net
import sys
n = int(sys.stdin.readline())
nums = list(map(int, sys.stdin.readline().split()))
cnt = 0
for n in nums:
if n != 1:
for i in range(2, n):
if n % i == 0:
break
else:
cnt += 1
print(cnt)주어진 수 N개 중에서 소수가 몇 개인지 찾아서 출력하는 프로그램 작성
> 소수가 뭔지는 압니다. 다만 어떻게 구현해야 하지..? 에 대해 고민하다 알고리즘 분류의 '에라토스테네스의 체'를 봤습니다. 위키피디아에서 보고, 코드도 어느정도 이해했습니다만은 모르겠습니다...
> 그래서 결국 검색했읍니다. nums반복문 안에서 range(2,n)을 하는 건 에라토스테네스의 체랑 같은 방식이겠쥬..?...
데이터분석 프로젝트<ver1>: K-드라마 프로그램, 출연진, 채널, 시청률 등의 TV 콘텐츠 DB 데이터
문화 빅데이터 - 포털- 전체 상품
www.bigdata-culture.kr
- 방송일자(BRDCST_DE, BRDCST_END_DE)와 시청률의 관계
대강의 EDA는 끝났으니, 위에 대해 보고자 한다.
data['BRDCST_DE']
data['BRDCST_END_DE']

그러나 방심은 금물..! 1월 1일이나 그 이후의 데이터도 있지는 않은지 보아야 할 것이다. 특히 종료일자의 경우 시작일자가 12월 31일 자정 가까운 시각이라면 1월 1일로 넘어갔을 가능성 또한 크다.
data[data['BRDCST_DE']>20211231]
data[data['BRDCST_END_DE']>20211231]

12개, 20개로 각각 데이터가 존재함을 확인했다. 둘을 묶어 없애버리자!
data[(data['BRDCST_DE']>20211231) | (data['BRDCST_END_DE']>20211231)].index
#인덱스를 확인한 뒤
data = data.drop(index=[5161, 5162, 5165, 5172, 5189, 5205, 5206, 5225, 5226, 5261, 5262,
5263, 5265, 5277, 5278, 5280, 5289, 5290, 5299, 5307], axis=0)
#드랍해주고
data.describe() #데이터에 잘 반영되었나 확인한다.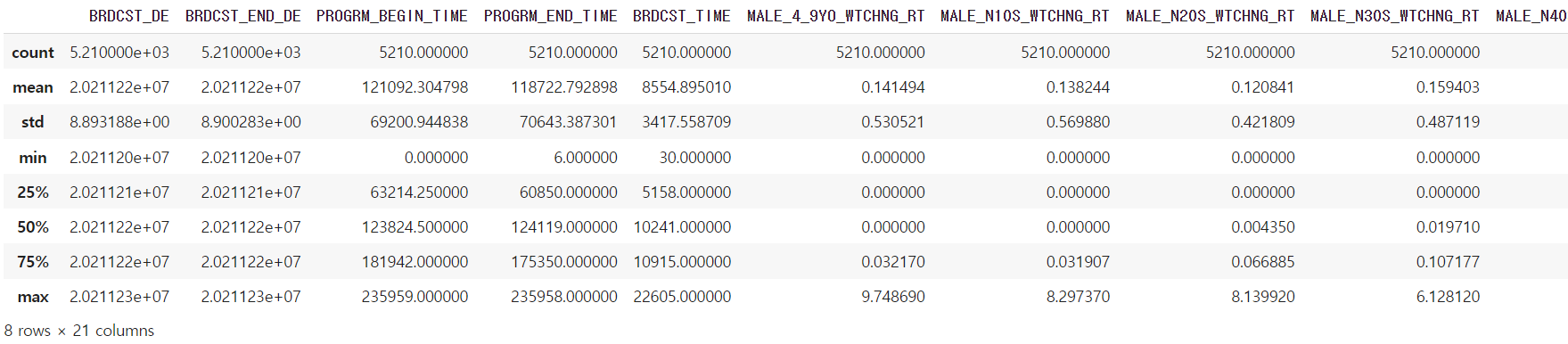
(++
data[data['BRDCST_DE']<20211201]
#혹시나 해서.. 2021년 12월 1일 전의 데이터는 없는지 확인했다.
#아무것도 출력되지 않았다.)
이제 방송일자에 대해 자세히 보아야 할 것이다. 슬라이싱을 하자니 int라서 안 되고.. str로 바꿔서 해야 할 것이다. 슬라이싱을 한다 쳐도 어떻게 하지? 고민하다 요일로 보아야 되겠다고 생각했다.
#2021년 12월 1일은 수요일이었다.
(20211201)%7 #수요일은 나누면 나머지가 3이다..?
20211202%7 #목요일은 나누면 나머지가 4다?!!?!?!우연이겠지만 이 놀라운 발견을 활용하기 위해 함수를 만들었다.
def brd_date(day):
if day % 7 == 3:
return 'WED'
elif day % 7 == 4:
return 'THR'
elif day % 7 == 5:
return 'FRI'
elif day % 7 == 6:
return 'SAT'
elif day % 7 == 0:
return 'SUN'
elif day % 7 == 1:
return 'MON'
else:
return 'TUE'
data['BRDCST_DAY'] = data['BRDCST_DE'].apply(brd_date)
data['BRDCST_END_DAY'] = data['BRDCST_END_DE'].apply(brd_date)
#만든 함수를 적용시킨 칼럼을 'BRDCST_DAY', 'BRDCST_END_DAY'라 명명했다.data.head()
#이제 시각화도 해보자
fig, ax = plt.subplots(1, 2)
ax[0].plot(data['BRDCST_DAY'], data['MALE_WTCHNG_RT'], '.', color='skyblue', alpha=0.5)
ax[1].plot(data['BRDCST_DAY'], data['FEMALE_WTCHNG_RT'], '.', color='violet', alpha=0.5)
plt.show()
날짜 중에서는 토요일과 일요일의 시청률이 높은 경향이 있어 보인다. (물론 제일 높은 시청률이 기록된 것이 토요일과 일요일인 것은 맞지만, 나머지 데이터의 분포를 보면 타 요일에 비해 낮은 경향이 있어 보이는 것도 사실이다. 즉 '극과 극'이 극명해 보인다.)
전체적으로는 남자보다 여자의 시청률이 더 높아보인다.
시각적으로 보았을 때는 대충 이런데, 실제 수치데이터로 보았을 때도 그럴까?
#토요일
m_nums = data[data['BRDCST_DAY']=='SAT']['MALE_WTCHNG_RT'].describe()
f_nums = data[data['BRDCST_DAY']=='SAT']['FEMALE_WTCHNG_RT'].describe()
m_nums - f_nums #토요일의 남자 시청률-여자 시청률.
min을 빼고 전부 다 마이너스 값이 나왔다. 이는 남성의 시청률보다 여성의 시청률이 훨씬 더 높음을 시사한다.
토요일 시청률 전반에서 여자의 시청률이 더 높은 경향이 있다. 그리고 그 차이는 중위수(50%)를 기준으로 V자를 그리듯 줄어들다 급격하게 커진 것 같다.
#일요일
m_nums2 = data[data['BRDCST_DAY']=='SUN']['MALE_WTCHNG_RT'].describe()
f_nums2 = data[data['BRDCST_DAY']=='SUN']['FEMALE_WTCHNG_RT'].describe()
m_nums2 - f_nums2 #일요일의 남자 시청률-여자 시청률.
min을 빼고 다 마이너스 값이 나온 것은 토요일과 동일하나, 그 차이가 조금 다르다.
일요일 시청률 전반에서 여자의 시청률이 더 높은 경향이 있다. 이 차이는 점점 커지는 경향이 있다. 즉 주말에 K-드라마를 즐기는 비율은 남성보다 여성이 월등히 높다고 할 수 있는 것이다.
토요일과 일요일의 남녀 시청률 차이를 비교하였을 때, 시청률의 전체적인 차이가 일요일에 훨씬 줄어들어있음을 알 수 있다. 그러나 이것을 보고 `남자들은 토요일보다 일요일에 드라마를 더 많이 본다`라고 할 수 있을까?
m_nums-m_nums2 #토요일 시청률-일요일 시청률.
남성의 최고 시청률이 일요일에 기록된 것은 맞지만, 전반적인 시청률은 토요일에 더 높음(25%와 최댓값을 제외하고는 모두 양수)을 알 수 있다.
이것이 최댓값에 휘둘리지(?)말아야 하는 이유이다..!
`여자의 드라마 시청률이 남자보다 높다`는 명제를 다른 수치로도 볼 수 있을까?
m_nums = data['MALE_WTCHNG_RT'].describe() #(모든 요일에 대한)남성의 시청률 데이터 수치요약
f_nums = data['FEMALE_WTCHNG_RT'].describe() #여성의 시청률 데이터 수치요약
m_nums - f_nums
최솟값(0)을 제외한 모든 구간에서 -가 나왔다. 이는 여자의 시청률이 남자의 시청률보다 전반적으로 더 높은 경향이 있음을 확실하게 알려준다!
그러나 아직 부족하다.. 더 확실하게 보고싶다!! 시각화도 해보고 싶다..! 해보자!!!!
fig, ax = plt.subplots(nrows=1, ncols=3, figsize=(21,5))
ax[0].hist(np.sqrt(np.sqrt(data['MALE_WTCHNG_RT'])))
ax[0].set_xlabel('MALE')
ax[1].hist(np.sqrt(np.sqrt(data['FEMALE_WTCHNG_RT'])))
ax[1].set_xlabel('FEMALE')
ax[2].hist(np.sqrt(np.sqrt(data['MALE_WTCHNG_RT']))-(np.sqrt(np.sqrt(data['FEMALE_WTCHNG_RT']))))
ax[2].set_xlabel('GENDER DIFF')
plt.show()
(np.sqrt(np.sqrt(data['MALE_WTCHNG_RT']))-(np.sqrt(np.sqrt(data['FEMALE_WTCHNG_RT'])))).kurt()
#첨도 구하기
정규분포의 첨도는 3이다. 그러나 3보다 훨씬 작은 첨도값을 가짐을 알 수 있다. 이는 정규분포가 더 중앙값에 몰린 경향이 크다(=차이가 0일 확률이 크다)는 것을 의미한다.
plt.hist(np.random.normal(0,0.2,5000), alpha=0.7) #평균이 0, 분산이 0.2(GENDER DIFF와 비교해보기 위함)인 정규분포
plt.hist(np.sqrt(np.sqrt(data['MALE_WTCHNG_RT']))-(np.sqrt(np.sqrt(data['FEMALE_WTCHNG_RT']))), alpha=0.7)
plt.show()
주황색이 성별 차이이다.
정규분포와 겹쳐 그려보았을 때 확실히 꼬리가 짧고(얇고) 봉우리가 높음을 알 수 있다.
주황색 그래프가 `남성의 시청률`-`여성의 시청률`의 그래프인 만큼, -에 조금 더 많은 값이 분포되어 있다는 것은 남성보다 여성의 시청률이 더 높은 경향이 있다는 것을 의미한다.
다시 요일별 시청률로 돌아오..고 싶은데 시간이 없다. 다음에 하는걸로..ㅎㅎ
'STUDY' 카테고리의 다른 글
| 파이썬 스터디 ver3. 1주차 (0) | 2022.06.27 |
|---|---|
| 파이썬 스터디 ver2. 5주차 (0) | 2022.05.16 |
| 파이썬 스터디 ver2. 3주차 (1) | 2022.05.08 |
| 파이썬 스터디 ver2. 2주차 (4) | 2022.04.05 |
| 파이썬 스터디 ver2. 1주차 (3) | 2022.03.31 |



