흑흑 약 3주간의 시험기간이 끝났씁니다... 물론 과제가 조금 남아있긴 하지만..
나름 정말 열심히 공부했는데 결과가 좋을진 모르겠어요. 거의 모든 과목이 준비해 온 방향과 다른 식의 문제로 구성되어 있었어서..ㅎㅅㅎ
열심히 공부했다는 거에 의의가 있죠 뭐..!
https://www.acmicpc.net/problem/10816
10816번: 숫자 카드 2
첫째 줄에 상근이가 가지고 있는 숫자 카드의 개수 N(1 ≤ N ≤ 500,000)이 주어진다. 둘째 줄에는 숫자 카드에 적혀있는 정수가 주어진다. 숫자 카드에 적혀있는 수는 -10,000,000보다 크거나 같고, 10,
www.acmicpc.net
import sys
n = int(sys.stdin.readline())
cards = sys.stdin.readline().strip().split(' ', n)
m = int(sys.stdin.readline())
nums = sys.stdin.readline().strip().split(' ', m)
dic = dict()
for i in cards:
if i in dic:
dic[i] += 1
else:
dic[i] = 1
for i in nums:
if i in dic:
print(dic[i], end=' ')
else:
print(0, end=' ')숫자 카드는 정수 하나가 적혀져 있는 카드이다. 상근이는 숫자 카드 N개를 가지고 있다. 정수 M개가 주어졌을 때, 이 수가 적혀있는 숫자 카드를 상근이가 몇 개 가지고 있는지 구하는 프로그램 작성.
> 처음엔 당연히 count를 썼습니다. 시간초과가 뜨길래 조금이나마 코드를 짧게 해주려고 별짓을 다했었어요.. 그래도 여전히 시간초과가 뜨길래 알고리즘 분류를 봤습니다. 자료구조, 정렬, 이분탐색이 있길래 검색해서 블로그 글 여러개 봤어요. 확실히 binary search를 쓰라는 것 같은데 이분탐색 함수를 해석하는 데만 해도 진이 빠져서 의욕이 사라졌습니다!
> 그래서 그냥 아예 다른 풀이를 가져왔습니다. 오랜만에 백준문제 푸려니까 너무 어렵네요...
https://www.acmicpc.net/problem/2164
2164번: 카드2
N장의 카드가 있다. 각각의 카드는 차례로 1부터 N까지의 번호가 붙어 있으며, 1번 카드가 제일 위에, N번 카드가 제일 아래인 상태로 순서대로 카드가 놓여 있다. 이제 다음과 같은 동작을 카드가
www.acmicpc.net
from collections import deque; import sys
n = int(sys.stdin.readline())
cards = deque(list(range(1, n+1)))
while len(cards) > 1:
cards.popleft()
cards.rotate(-1)
print(cards.pop())N장의 카드가 있다. 각각의 카드는 차례로 1부터 N까지의 번호가 붙어 있으며, 1번 카드가 제일 위에, N번 카드가 제일 아래인 상태로 순서대로 카드가 놓여 있다.
이제 다음과 같은 동작을 카드가 한 장 남을 때까지 반복하게 된다. 우선, 제일 위에 있는 카드를 바닥에 버린다. 그 다음, 제일 위에 있는 카드를 제일 아래에 있는 카드 밑으로 옮긴다. N이 주어졌을 때, 제일 마지막에 남게 되는 카드를 구하는 프로그램 작성.
> 일단 문제 먼저 이해하고 알고리즘을 어떻게 짜야하나 고민하다 알고리즘 분류를 봤습니다. '자료구조', '큐'. 그래서 큐 관련 글을 보다가 deque에 rotate라는 게 있다더라 해서 혹시 하고 써보니 맞았어요!!! ㅠㅠㅠ 1트만에 성공한거 진짜 오랜만이에요 너무 감격스러움..
> 아래 블로그를 특히 참조했습니다!!
https://leonkong.cc/posts/python-deque.html
Python - 데크(deque) 언제, 왜 사용해야 하는가?
Python의 데크(deque)에 대해 알아보고 언제, 왜 써야 하는지 살펴본다
leonkong.cc
데이터분석<ver0.75>: K-드라마 프로그램, 출연진, 채널, 시청률 등의 TV 콘텐츠 DB 데이터
문화 빅데이터 - 포털- 전체 상품
www.bigdata-culture.kr
- 저번 주에 아주 큰 뻘짓을 해서, 여전히 EDA다. 갈 길이 멀다. 화이팅!
- 아래는 컬럼들에 대한 설명이다.
data.info() #데이터 다시보기
이를 토대로 다음과 같은 물음들을 생각해 볼 수 있다.
data['MALE_WTCHNG_RT'] = (data['MALE_4_9YO_WTCHNG_RT']+data['MALE_N10S_WTCHNG_RT']+data['MALE_N20S_WTCHNG_RT']+data['MALE_N30S_WTCHNG_RT']+data['MALE_N40S_WTCHNG_RT']+data['MALE_N50S_WTCHNG_RT']+data['MALE_N60S_ABOVE_WTCHNG_RT'])/7
data['FEMALE_WTCHNG_RT'] = (data['FEMALE_4_9YO_WTCHNG_RT']+data['FEMALE_N10S_WTCHNG_RT']+data['FEMALE_N20S_WTCHNG_RT']+data['FEMALE_N30S_WTCHNG_RT']+data['FEMALE_N40S_WTCHNG_RT']+data['FEMALE_N50S_WTCHNG_RT']+data['FEMALE_N60S_ABOVE_WTCHNG_RT'])/7
#각 나이대의 시청률을 다 더한 뒤 7(나이대 개수)로 나누었다(=평균)
data['MALE_WTCHNG_RT']
data['FEMALE_WTCHNG_RT']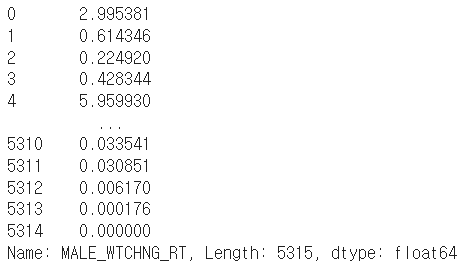

어..? 5314번째 인덱스는 선호도 자료가 없나? 그렇다면 이런 데이터가 더 있나?
data[(data.iloc[:,-1]==0) & (data.iloc[:,-2]==0)] #시청률 평균이 0인지 확인
data[(data.iloc[:,-1]==0) & (data.iloc[:,-2]==0)].index #인덱스 확인
data = data.drop(index=[70, 162, 439, 455, 559, 613, 619, 620, 748, 749, 904,
968, 1109, 1160, 1253, 1305, 1497, 1526, 1527, 1698, 1699, 1743,
1801, 1825, 1826, 1869, 1947, 1948, 2026, 2122, 2131, 2152, 2300,
2301, 2304, 2498, 2713, 2714, 2764, 2884, 2992, 2997, 3022, 3023,
3142, 3143, 3317, 3497, 3498, 3685, 3770, 3869, 3883, 3884, 3885,
3914, 3915, 3964, 4048, 4049, 4091, 4092, 4229, 4230, 4231, 4257,
4258, 4403, 4409, 4619, 4620, 4624, 4665, 4690, 4806, 4807, 4825,
4845, 5004, 5134, 5174, 5187, 5190, 5212, 5314], axis=0)
#1의 결과 복사-붙여넣기 해 제거해주기
data.describe() #잘 제거되었는지 확인(count에 유의)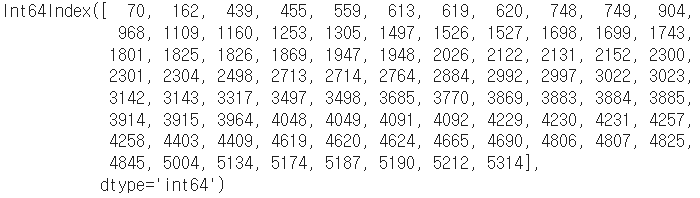

5315-85=5230. 잘 제거되었음을 확인할 수 있다!
그런데 이 때 궁금한 게 있다. 과연 남성 시청률이 높으면 여성 시청률도 높을까?(둘 사이에 선형관계가 있을까?)
import matplotlib.pyplot as plt; import seaborn as sns
sns.lmplot(x='MALE_WTCHNG_RT', y='FEMALE_WTCHNG_RT', data=data) #아주 강한 선형관계가 있다.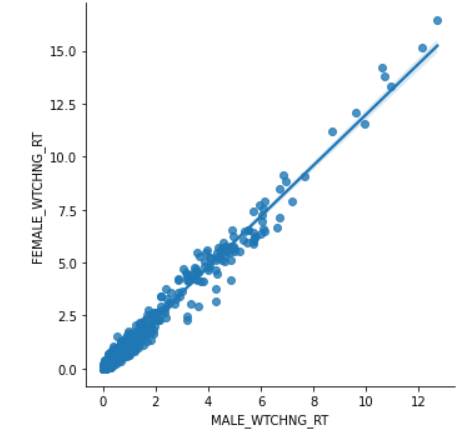
선형회귀 직선을 그려보았다. 놀랍게도 거의 직선에 가깝다!!! ㅇ0ㅇ 우리는 보통 장르에 따라 성별 선호도가 다를 것이라고 생각하는데 데이터는 그것이 틀린 추측이라고 말해주는 듯 하다..!
상관관계에 대해서도 구해보자.
np.corrcoef(data['MALE_WTCHNG_RT'], data['FEMALE_WTCHNG_RT'])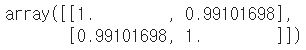
1에 놀라우리만치 가까운 값이 도출되었다. 이로써 우리는 남성의 시청률과 여성의 시청률은 선형관계를 가지며 상관관계 또한 매우 큼을 확인했다!
이제 시청률에 대한 탐색은 어느정도 끝났으니, 다음부터 본격적으로
'STUDY' 카테고리의 다른 글
| 파이썬 스터디 ver2. 5주차 (0) | 2022.05.16 |
|---|---|
| 파이썬 스터디 ver2. 4주차 (0) | 2022.05.12 |
| 파이썬 스터디 ver2. 2주차 (4) | 2022.04.05 |
| 파이썬 스터디 ver2. 1주차 (3) | 2022.03.31 |
| 파이썬 스터디 10주차 (3) | 2022.03.18 |



