구름 X 전주 ict 이노베이션 스퀘어의 온라인 코딩교육 과정 중, 세미 팀프로젝트 진행 내용을 정리하였습니다.
!전체 프로젝트 내용이 아닌 !제가 한 부분만! 정리하였습니다!
1차 팀프로젝트: 대구광역시 관광소비 추이 분석(2018~2021)
(데이터 출처: 한국관광 데이터랩, https://datalab.visitkorea.or.kr/)
df = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/20220701154437_관광소비 추이.csv', encoding='euc-kr')
df.head(3) #데이터프레임 불러오고 확인하기
df의 형태는 위와 같다. 총소비, 호텔, 콘도, 등등 총 19종의 중분류 이후 2019년도의 총소비, 호텔, 콘도 등등 18종의 중분류 데이터가 나오는 식이다.
df2018 = df[df['기준년월']==2018]
df2018['ratio'] = (df2018['지출액'] / df2018.iloc[0, 3]) * 100 #2018년의 중분류별 지출액 비율
df2018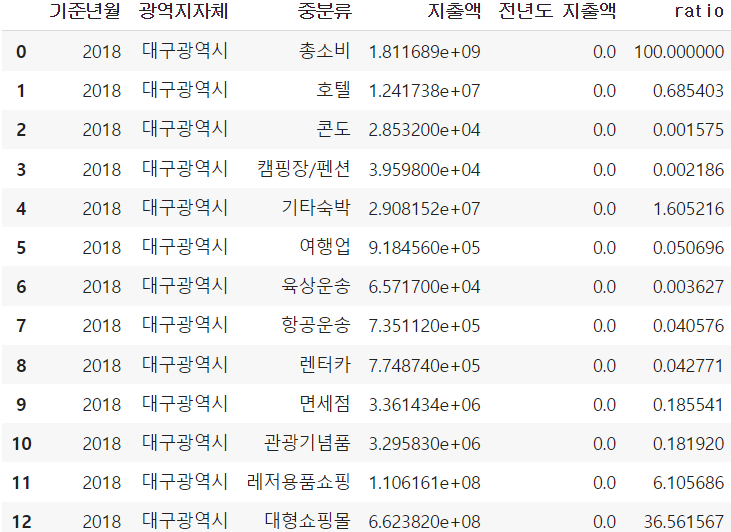
ratio라는 컬럼을 만들어 총소비 지출액 대비 각 중분류의 지출액 퍼센트를 볼 수 있게 했다. 위 캡쳐에서는 짤렸지만 df2018의 경우 총 19개의 로우값을 가지며 ratio가 가장 높은 것은(총소비 제외) 식음료로, 약 50.3의 ratio값을 가졌다.
이같은 방법으로 df2018, df2019, df2020, df2021도 만들었으나 for문을 써서 한번에 데이터를 정리해 모았다면 더 효율적이지 않았을까 싶다.. 그 점이 매우 아쉽다
팀원 중 한 분이 레저산업 관련 소비 비중을 보면 어떻냐 하셔서 중분류들 중 레저와 가깝게 보이는 '레저용품쇼핑', '캠핑장/펜션', '기타레저'를 모아 leisure라는 데이터프레임을 만들었다.
leisure = df[(df['중분류'] == '레저용품쇼핑') | (df['중분류'] == '캠핑장/펜션') | (df['중분류'] == '기타레저')]
leisure['지출액'].sum() / df[df['중분류']=='총소비']['지출액'].sum()
#중분류=='레저용품쇼핑' | '캠핑장/펜션' | '기타레져'를 leisure라고 묶어 총지출액과 비교
#총지출액 대비 leisure의 지출액(합)은 약 0.08로 매우 적은 비중을 차지하는 것을 알 수 있었음
df1_sums = df1[df1['중분류']=='총소비']
df1_sums #중분류가 '총소비'인 것들만 모아 만들기
df_sums를 활용하여 각 해마다 leisure가 차지하는 지출액 비중을 구해보자
leisure[leisure['기준년월']==2018]['지출액'].sum() / df1_sums[df1_sums['기준년월']==2018]['지출액']
leisure[leisure['기준년월']==2019]['지출액'].sum() / df1_sums[df1_sums['기준년월']==2019]['지출액']
leisure[leisure['기준년월']==2020]['지출액'].sum() / df1_sums[df1_sums['기준년월']==2020]['지출액']
leisure[leisure['기준년월']==2021]['지출액'].sum() / df1_sums[df1_sums['기준년월']==2021]['지출액']
#순서대로 0.083924, 0.080674, 0.073811, 0.071364가 나왔다. 시간이 갈수록 비중이 줄어들었다.
sns.lineplot(x='중분류', y='지출액', hue='기준년월', data=leisure)
hue를 기준년월(연도)로 두고 각각의 플롯을 그려보아도 leisure 지출액의 비율이 지속적으로 감소하고 있다는 것을 알 수 있었다.
plt.plot('기준년월', '지출액', data=leisure[leisure['중분류']=='캠핑장/펜션'])
plt.legend() #캠핑장/펜션의 데이터만 따로 떼어내기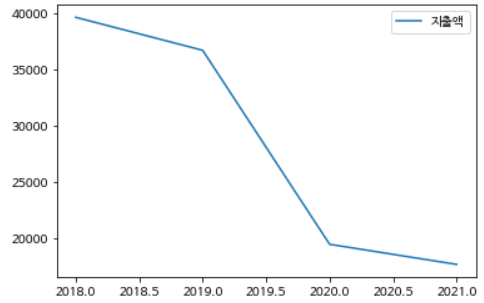
위에서 캠핑장/펜션의 데이터 값이 너무 미미해보여 따로 플롯을 그려보았다. 이 또한 감소세를 보인다.
df_sums = df[df['중분류']=='총소비']
plt.plot('기준년월', '지출액', '--p', data=df_sums)
plt.legend() #중분류==총소비의 지출액 추이
전체 지출액 또한 하락세를 보이다 코로나19가 있었던 2020년 급감한 모양새이다.
df_notsum = df[df['중분류']!='총소비']
df_notsum #중분류가 총소비가 아닌 것들 모아보기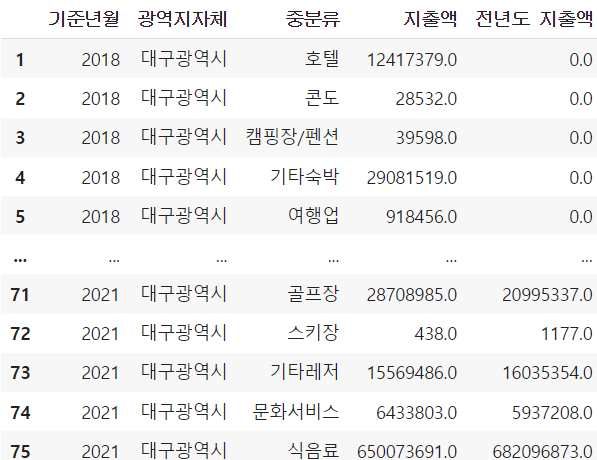
sns.lineplot(x='기준년월', y='지출액', hue='중분류', data=df_notsum)
plt.legend(loc='upper right') #중분류!=총소비의 지출액 추이 #레전드는 오른쪽 위
여기도 loc가 아니라 bbox_to_anchor를 썼으면 좋았을 걸ㅠ 아쉽다. 여하튼 보기 좋지않다..
df2 = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/20220701154437_업종별 지출액.csv', encoding='euc-kr')
df2 #다른 데이터 불러오기
여기도 조금 잘리긴 했지만(총 로우는 18개로, 대분류는 쇼핑/숙박/식음료/여가서비스/여행/운송의 6가지가 있다.) 잘 불러온 것 같다. 대분류와 대분류 지출액 비율, 중분류 지출액 비율이 추가된 듯 하며 연도구분이 따로 없어 보인다.
wedgeprops={'width': 0.7, 'edgecolor': 'w', 'linewidth': 5}
labels=['쇼핑업', '숙박업', '식음료업', '여가서비스업', '여행업', '운송업']
plt.pie([44.6, 2.3, 49.0, 4.0, 0.0, 0.1], autopct='%.1f%%', pctdistance=0.85, wedgeprops=wedgeprops)
plt.legend(labels=labels, bbox_to_anchor=(1, 0)); plt.show()
sns.barplot(x='대분류', y='대분류 지출액 비율', data=df2)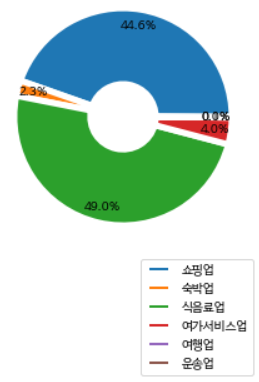

(플랏만 봐서 몰랐는데 코드 보니까.. ㅋ..ㅋㅋㅋ...ㅋㅋㅋㅋㅋ 제가.. 대분류 지출액 비율 값을 그대로 가져왔었구나.. 아..ㅋㅋㅋㅋㅋㅋ 너무 부끄럽네요ㅋㅋㅋㅋㅋ)
여하튼.. 이렇게.. ^~^ 나름 예쁜 대분류 지출액 비율의 파이플랏과 바플랏을 그려보았습니다. 비율 내림차순으로 본다면 식음료, 쇼핑, 여가서비스, 숙박, 운송, 여행업인데 여행업은 보이지도 않는 것 같네요.
def Cat(cat):
if (cat == '관광기념품') | (cat=='대형쇼핑몰') | (cat=='레저용품쇼핑') | (cat=='면세점'):
return '쇼핑업'
if (cat=='기타숙박') | (cat=='캠핑장/펜션') | (cat=='콘도') | (cat=='호텔'):
return '숙박업'
if cat=='식음료':
return '식음료업'
if (cat=='골프장') | (cat=='관광유원시설') | (cat=='기타레저') | (cat=='문화서비스') | (cat=='스키장'):
return '여가서비스업'
if cat=='여행업':
return '여행업'
if (cat=='렌터카') | (cat=='육상운송') | (cat=='항공운송'):
return '운송업'
df_notsum['대분류'] = df_notsum['중분류'].apply(Cat)
df_notsum #중분류 칼럼에 Cat이라는 함수를 적용시킨 값을 대분류에 할당
데이터 개수가 맞지 않아 병합이 원활하지 않을 것 같아.. 함수를 만들어 기존의 데이터프레임(처음 불러온 df)에 적용시켰씁니다. 이를 토대로 한 플랏들을 그려볼 예정입니다.
sns.lineplot(x='대분류', y='지출액', hue='기준년월', data=df_notsum)
sns.lineplot(x='기준년월', y='지출액', hue='대분류', data=df1_notsum)
plt.legend(loc='upper left')

hue를 기준년월로, 대분류로 그려 본 라인플랏들입니다. 기준년월에 2018.0, 2018.5 이런 식으로 있는 거 보기에 좀 불편한데.. 가공할 걸 그랬나봐요. 그땐 왜 괜찮다고 생각해서 그대로 냅뒀던걸까요...
datas = pd.read_excel('/content/colaborated_data22-7-5.xlsx')
datas
이 데이터는 위에서 따로 보았던 leisure값들만 모아 가공한 것이다. 이를 활용해 그래프를 그려보자~!
sns.lineplot(x='년도', y='레저종합/총소비', hue='지역', data=datas)
plt.legend(loc='upper right')
sns.lineplot(x='년도', y='레저종합 지출액', hue='지역', data=datas)
plt.legend(loc='upper right')
sns.lineplot(x='년도', y='총소비', hue='지역', data=datas)
plt.legend(loc='upper right')


왼쪽은 레저의 소비'비중', 중간은 레저의 소비'(총)금액', 왼쪽은 총소비 그래프이다. 비중으로 보았을 땐 광주가 제일 높고 서울이 제일 낮았으나 금액으로 보았을 땐 서울의 지출액을 타 지역들이 따라가지 못했다. 이는 왼쪽의 총소비 그래프에서도 알 수 있듯이, 서울의 총소비금액이 타 지역에 비해 압도적으로 많기 때문(그만큼 인구가 많기 때문)일 것이다.
뭐 이렇게.. 총소비 데이터 분석 결과는 "코로나19 이후 전체 소비량이 줄었으며 이는 레저산업에서도 마찬가지다. 다만 일부 지역(인천)의 경우 그 영향을 받지 않은 것처럼 보인다" 쯤으로 정리할 수 있을 것 같습니다.
2차 팀프로젝트: 농산물 가격에 영향을 미치는 요인 분석(기후)
(데이터 출처: 농산물유통정보, https://www.kamis.or.kr/customer/price/bizcondition/period.do)
base_df = pd.read_excel("/content/drive/MyDrive/Colab Notebooks/구름 프로젝트/market-price2012-2022.xlsx")
display(base_df.head())
weather_data = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/구름 프로젝트/2012_2022기상데이터.csv", encoding='cp949')
display(weather_data.head())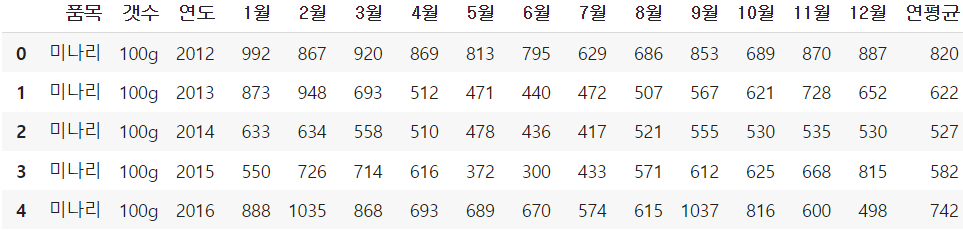

농산물 가격 정보를 base_df, 기후데이터를 weather_data라고 명명했습니다.
우선 base_df라 명명한 농산물 데이터부터 가공해보죠!
base_df = base_df[base_df['연도']!=2022].reset_index(drop=True)
base_df['품목'].unique() #['미나리', '배', '배추', '복숭아', '사과', '쌀', '애호박']미나리 = base_df[base_df['품목']=='미나리']
미나리.drop(['품목', '갯수'], axis=1, inplace=True) #품목과 갯수는 다 똑같으니 드랍
미나리
연도가 2022까지 기록되어 있어 2022 데이터를 제외하였습니다. 2018년 9월의 데이터가 0인 것을 보아 아마 결측치인 것 같아 처리해주기로 합니다.
미나리.loc[6, '9월'] = 미나리['9월'].mean() #결측치 평균으로 메꿈
미나리['9월'] = 미나리['9월'].astype('int') #int로 바꿈
미나리 #0 -> 646plt.figure(figsize=(12, 8))
미나리.loc[:, '연도':'12월'].set_index('연도').T.plot()
plt.title('미나리'); plt.legend(bbox_to_anchor=(1, 1))
연도를 레전드로 처리해주고 싶어서 index로 설정했습니다. 조금 산만하긴 한데 추이는 대충 보이는 것 같아요.
다른 것도 같은 식으로 처리하되, 복숭아 사과같은 과일들은 "여름~가을"에만 데이터가 있어 0을 결측치로 처리하지 않았습니다.
이제 기후데이터를 봅시다.
weather_df = weather_data.loc[:,['일시', '평균기온(°C)', '최고기온(°C)', '최저기온(°C)', '평균상대습도(%)',
'월합강수량(00~24h만)(mm)', '평균풍속(m/s)', '일조율(%)', '평균지면온도(°C)']]
weather_df.columns = ['일시', '평균기온', '최고기온', '최저기온', '평균습도', '월강수량', '평균풍속', '일조율', '평균지면온도']
weather_df.head()

필요하다고 생각되는 컬럼들만 모으고 컬럼명도 깔끔하게 바꿔줬습니다.
이후에 info()로 dtype을 보는데 일시가 object더라구요? 이를 활용해서 아래 과정을 진행했습니다.
lst = list(weather_df['일시'].values)
print(lst[:5]) #['2012-01', '2012-02', '2012-03', '2012-04', '2012-05']
year = []
month = []
for i in range(len(lst)):
year.append(lst[i][:4])
month.append(lst[i][5:])
year[:5], month[:5] #(['2012', '2012', '2012', '2012', '2012'], ['01', '02', '03', '04', '05'])weather_df['year'] = pd.Series(year)
weather_df['month'] = pd.Series(month)
weather_df.head()
일시 컬럼 값들을 갖는 리스트 lst를 만들어 슬라이싱으로 year리스트와 month리스트를 만든 뒤 weather_df의 컬럼으로 값을 넣어주었습니다.
pd.pivot_table(weather_df, index='month', columns='year', values='평균기온')
base_df와 그나마 비슷한 형태를 만들고 싶어서 피봇테이블을 만들었습니다. 2022년 데이터는 아직 다 나오지 않아 NaN인 것 같습니다.
weather_df_not2022 = weather_df[yrs!='2022']
avg_temp = pd.pivot_table(weather_df_not2022, index='month', columns='year', values='평균기온')
avg_temp
avg_temp.plot()


그래서 2022년 데이터를 뺀 df를 만들고(왼쪽) 이를 바탕으로 피봇테이블을 만든 뒤(중간) 플랏을 그렸습니다(오른쪽). 월별 평균기온의 플랏인데, 년도에 따른 차이는 딱히 없는 것 같습니다.
같은 방식으로 다른 날씨요인에도 적용하였습니다.
fig, axs = plt.subplots(3, 4, figsize=(16, 12))
fig.tight_layout()
cat1 = 미나리.loc[:,'연도':'12월'].set_index('연도')
cat1.T.plot(ax=axs[0, 0])
axs[0, 0].set_title('미나리')
axs[0, 0].legend(bbox_to_anchor=(-0.25, -0.35))
cat2 = 배.loc[:,'연도':'12월'].set_index('연도')
axs[0, 1].plot(cat2.T)
axs[0, 1].set_title('배')
cat3 = 배추.loc[:, '연도':'12월'].set_index('연도')
axs[0, 2].plot(cat3.T)
axs[0, 2].set_title('배추')
cat4 = 복숭아.set_index('연도').loc[:,'6월':'10월']
axs[0, 3].plot(cat4.T)
axs[0, 3].set_title('복숭아')
cat5 = 사과.set_index('연도').loc[:,'7월':'12월']
axs[1, 0].plot(cat5.T)
axs[1, 0].set_title('사과')
cat6 = 쌀.loc[:, '연도':'12월'].set_index('연도')
axs[1, 1].plot(cat6.T)
axs[1, 1].set_title('쌀')
cat7 = 애호박.loc[:, '연도':'12월'].set_index('연도')
axs[1, 2].plot(cat7.T)
axs[1, 2].set_title('애호박')
wea_temp = pd.pivot_table(weather_df_not2022, index='month', columns='year', values='평균기온')
axs[1, 3].plot(wea_temp)
axs[1, 3].set_title('평균기온')
wea_rain = pd.pivot_table(weather_df_not2022, index='month', columns='year', values='월강수량')
axs[2, 0].plot(wea_rain)
axs[2, 0].set_title('월강수량')
wea_sunn = pd.pivot_table(weather_df_not2022, index='month', columns='year', values='일조율')
axs[2, 1].plot(wea_sunn)
axs[2, 1].set_title('일조율')
wea_grnd = pd.pivot_table(weather_df_not2022, index='month', columns='year', values='평균습도')
axs[2, 2].plot(wea_grnd)
axs[2, 2].set_title('평균습도')
wea_grnd = pd.pivot_table(weather_df_not2022, index='month', columns='year', values='평균풍속')
axs[2, 3].plot(wea_grnd)
axs[2, 3].set_title('평균풍속')
plt.show()
코드가 조금.. 가독성이 떨어지긴 하는데 위에서 쓴 방식들을 거의 그대로 썼습니다. 분석 결과는 '월 강수량이 가장 높았던 2020년에 배추와 애호박의 가격이 가장 높았기에, 강수량은 배추와 애호박의 가격과 어느정도 상관이 있다'는 것입니다.
통계분석을 하면 좋았겠지만 어떤 데이터를 기준으로 무엇을 해야할지 감을 잡지 못했습니다...
알고 있던 것들, 해 봤던 것들이라고 생각했음에도 새로운 데이터를 접하면 항상 헤메게 되네요. 열심히 공부해야죠 머... ㅎㅎㅎ 프로그래머스 문제는 언제 또 풀지.. ^ㅠ^
'STUDY' 카테고리의 다른 글
| 파이썬 스터디 ver3. 7주차 (2) | 2022.08.14 |
|---|---|
| 파이썬 스터디 ver3. 6주차 (3) | 2022.08.06 |
| 파이썬 스터디 ver3. 4주차 (1) | 2022.07.24 |
| 파이썬 스터디 ver3. 3주차 (0) | 2022.07.14 |
| 파이썬 스터디 ver3. 2주차 (1) | 2022.07.06 |



