2022.07.18~2022.07.29
구름 X 전주 ict 이노베이션 스퀘어의 온라인 코딩교육 내용을 정리하였습니다. 팀 프로젝트 내용은 5주차에 있습니다.
이번엔 (이전에 아주 간단하게 배운 적 있는)SQL에 대해 배워서 SQL관련 내용이 특히나 많습니다.
numpy, pandas 복습
lst = np.arange(1, 10, 2)**2 #range(1, 10, 2)에 제곱한 값
lst #array([ 1, 9, 25, 49, 81], dtype=int32) #이런 식으로 연산 수행 가능(ndarray의 기능)temp = np.arange(4) #형태 (4,)
temp_1 = temp.reshape(1, 4) #형태 1x4로 변경 #array([[0, 1, 2, 3]])
temp_2 = temp.reshape(2, -1) #열 차원계산 알아서 #array([[0, 1], [2, 3]])
temp_3 = temp.reshape(2, 2, order='F') #열부터 채우기 #array([[0, 2], [1, 3]]))v = np.array([[1, 2], [3, 4]])
np.max(v), np.min(v), np.max(v, axis=0), np.max(v, axis=1), np.multiply(v, v), np.dot(v, v)
#(4, 1, array([3, 4]), array([2, 4]), array([[1, 4], [9, 16]]), array([[7, 10], [15, 22]])
#v의 최대값, v의 최소값, v의 (열방향)최대값, v의 (행방향)최대값, v*v, np.dot은 외적s = pd.Series([1, 2, 3])
s.values, s.index #(array([1, 2, 3]), RangeIndex(start=0, stop=3, step=1))
ss = pd.Series([1, 2, 3], index=['a', 'b', 'c'])
ss.values, ss.index #(array([1, 2, 3]), Index(['a', 'b', 'c'], dtype='object'))
EDA(Exploratory Data Analysis): 탐색적 데이터분석
df['gender'] = df['gender'].replace([1, 2], ['male', 'female'])
#gender컬럼의 1, 2를 male, female로 바꿈
df.mean() #각 컬럼들의 평균을 보여줌- 왜도: 분포가 좌우로 치우쳐진 정도. 꼬리가 왼쪽이면 음수, 꼬리가 오른쪽이면 양수. `df['컬럼명'].skew()`
- 첨도: 분포가 뾰족한 정도. `df['컬럼명'].kurtosis()`. 왜도가 0, 첨도가 1일 때 완전한 정규분포라고 할 수 있다.
- sns.jointplot: 산점도와 히스토그램을 함께 그려준다. kind='kde'(오른쪽)로 하면 영역들을 등고선으로도 볼 수 있다.
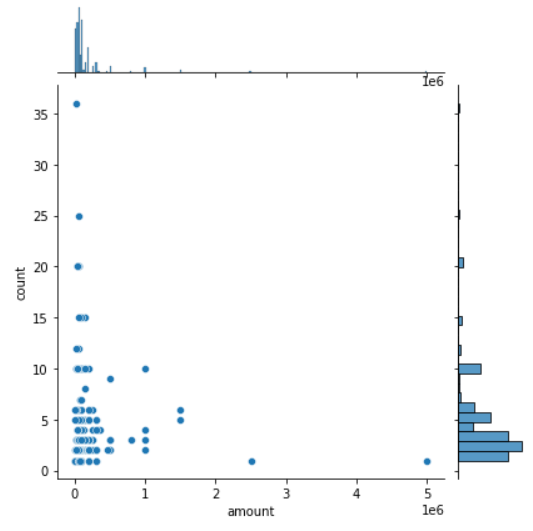

- IQR(InterQuartile Range): 3사분위수(0.75)에서 1사분위수(0.25)를 뺀 값. box-whisker plot의 이상치는 1사분위수-1.5IQR보다 작거나 3사분위수+1.5IQR보다 큰 값을 말한다.
- 로그함수: 큰 수를 같은 비율의 작은 수로 바꿔주어 데이터 분포의 왜도/첨도가 큰 경우 데이터 정규성을 높이는 것을 돕는다. `np.log`
pd.crosstab(df.propensity, df.skin, margins=True) #두 변수를 쉽게 볼 수 있도록 함
#margins=True로 합계 표시 #파라미터에 normalize=True로 하면 표준화해서 볼 수도 있음(합계=1)
- 카이제곱(Chi-square) 검정: 두 범주형 변수 사이의 빈도 차이에 의미가 있는지 검정. `stats.chisquare(a, b)`
- 귀무가설(null hypothesis)는 관계/차이 없음(독립), 대립가설(alternative hypothesis)는 관계/차이 있음(독립x).
- p-value: 데이터의 통계량이 귀무가설을 지지하는 정도. 귀무가설이 참이고 현재의 통계량 차이가 우연이라 가정하였을 때, 같은 결과가 나올 확률. p-value가 0.05미만이면 '두 변수 사이에 유의미한 차이가 있다'고 보며 대립가설 채택(혹은 귀무가설 기각).
- ANOVA(ANalysis Of VAriance): 분산분석. 설명변수가 범주형이고 종속변수가 연속형일 때 두 집단 간 비교분석에 사용. 분산 개념을 활용하므로 편차 제곱합을 자유도로 나누어 얻은 값을 사용한다. (1)각 데이터는 서로 독립이고 (2)각 데이터는 정규분포를 따르는 모집단에서 추출되었으며 (3)데이터들의 모집단의 분산이 동일하다는 것을 가정.
- 상관계수: 두 변수의 "선형관계"를 의미하는 정도. 인과관계를 뜻하지 않으므로 실제로 의미가 있는지 보려면 p-value를 함께 고려해주는 것이 좋다. 절대값이 1에 가까우면 양/음의 상관관계를, 0이면 상관관계를 갖지 않는다고 본다. 주로 피어슨 상관계수를 사용한다. `~.corr()`
- sns.pairplot: 데이터 내의 각 컬럼별 상관관계, 값 특성을 한 눈에 보여주는 그래프. 아래 코드는`sns.set(style='ticks', color_codes=True)`, `sns.pairplot(iris, kind='reg)`로 그린 것이다. kind=reg는 선형회귀모델의 추세선을 그려준다.

- 심슨의 역설: 데이터 전반을 보았을 때와 세부적으로 보았을 때 결과가 다른 것. 아래는 신장결석 치료방법 예시로, 작은 결석과 큰 결석 치료방법 성공률을 단순히 평균낸 경우(=작은 결석과 큰 결석을 동일하게 취급함)이다.
| 방법 A | 방법 B | |
| 작은 결석 | 93 % (81/87) | 87 % (234/270) |
| 큰 결석 | 73 % (192/263) | 69 % (55/80) |
| 총합 | 78 % (273/350) | 83 % (289/350) |
DataBase
- DBMS: DataBase Management System. 하드웨어의 DB를 관리해주는 소프트웨어. 계층형, 관계형, 객체형이 있으며 현재는 관계형 데이터베이스를 다루는 Relational DBMS인 Oracle, MySQL(MariaDB), SQLite 등이 널리 쓰인다.
- 데이터 모델링 3단계: 현실세계 --개념적 데이터 모델링--> E-R다이어그램(개념 스키마) --논리적 데이터 모델링--> Relation모델(논리적 스키마) --물리적 데이터 모델링--> 물리적인 SQL코드(데이터베이스 스키마)
- 개념적 데이터 모델링: 현실세계로부터 Entity(개체)를 추출하고 Entity들 간의 관계를 정의해 Entity-Relationship 다이어그램을 만드는 과정. 여기서 개체란 '저장 가치가 있는 중요 데이터를 가진 사람, 사물', 속성은 '의미있는 데이터의 가장 작은 논리 단위', 관계는 '개체와 개체 사이의 연관성, 대응 관계(매핑)'.
- 논리적 데이터 모델링: E-R다이어그램을 바탕으로 DB에 저장할 논리구조를 Relation모델로 표현하는 과정. 여기서 릴레이션이란 '개체에 대한 데이터를 2차원 테이블로 표현한 것', 릴레이션 내의 속성은 '열column==필드field 개념', 튜플은 '행row==레코드record==인스턴스instance 개념', 차수degree는 '릴레이션 내 속성(컬럼) 개수', 카디널리티carinality는 '릴레이션 내 튜플(로우) 개수'를 말한다.
- 물리적 데이터 모델링: Relation모델을 DBMS종류에 따라 물리적 저장장치에 저장할 수 있도록 물리적 구조(SQL 등)로 구현하는 과정.
- SQL: Structured Query Language, 구조적 질의 언어. DataBase에게 (데이터를)요청해 관리/처리하기 위한 언어. 표준은 ANSI SQL.
- DDL: Data Definition Language, 데이터 정의 언어. 각 릴레이션(DB 테이블)을 정의할 때 사용한다. CREATE(테이블 생성), ALTER(테이블 변경), DROP(테이블 삭제).
- DML: Data Manipulation Language, 데이터 조작 언어. 데이터 관리를 위해 사용한다. SELECT(읽기), INSERT(추가), UPDATE(수정), DELETE(지우기).
- DCL: Data Control Language, 데이터 제어 언어. 사용자 관리와 사용자별 권한(릴레이션이나 데이터에 대한 관리, 접근)을 다루기 위해 사용한다. GRANT(권한 부여), REVOKE(권한 해제).
SELECT 'poop' --고유값은 따옴표로 감쌈
FROM ~~~
INNER JOIN ~~ ON ~.~ = ~.~
WHERE ~~~
GROUP BY ~~~
HAVING ~~~
ORDER BY ~~~
LIMIT~ OFFSET~; --명령은 ;로 끝내야 함
/* 주석
주석(여러 줄) */ --주석(한 줄)- `import sqlite3`으로 python에서 SQLite를 사용할 수 있다.파이썬에 내장되어 있으므로 따로 설치 불필요.
import sqlite3
dbpath = "temp.db" #db파일 불러오기 혹은 만들기
conn = sqlite3.connect(dbpath) #db파일에 연결
cur = conn.cursor() #커서(심부름꾼) 만듦
cur.execute('~~') #SQL문 하나 실행시키기
conn.commit() #저장
conn.rollback() #마지막 commit(저장) 이후의 변경사항 모두 취소
conn.close() #연결 끊기- SQLite3의 데이터타입들: NULL, INTEGER, REAL(소수), TEXT(문자열), BLOB(binary large object, 이미지나 바이너리 파일(이게 뭔지 모르겠어요...))
script = """
CREATE TABLE employees(
id INTEGER PRIMARY KEY,
name TEXT NOT NULL,
salary REAL,
department TEXT,
position TEXT,
hireDate TEXT)
"""
cur.execute(script) #SQL문 하나는 execute로 실행
conn.commit() #저장- 위 코드는 employees라는 테이블을 만든 것이다. employees는 primary key이자 정수값을 갖는 id컬럼, 문자열이면서 null이 아닌 name컬럼, 실수인 salary컬럼, 문자열인 department, position, hiredate컬럼을 가진다.
script = """
--1) employees 테이블이 이미 있다면 제거
DROP TABLE IF EXISTS employees;
--2) employees 테이블 생성
CREATE TABLE employees(
id INTEGER PRIMARY KEY AUTOINCREMENT, --숫자를 저장, 이 테이블의 주요 Key(기본 키)로 지정, 값을 따로 입력하지 않으면 자동 증가 숫자 부여
name TEXT NOT NULL, --빈 값이 저장되는 것을 허용하지 않음
salary REAL, --소수점이 들어간 자료형
department TEXT,
position TEXT,
hireDate TEXT);
--3) employees 테이블에 데이터(row == record == instance) 넣기
--Format) INSERT INTO 테이블명(필드명, 필드명, ...) VALUES(실제값, 실제값, ...) <- 지정한 필드의 수와 넣어주는 값의 갯수가 동일해야 함
INSERT INTO employees(name, salary, department, position, hireDate) VALUES('Dave', 300, 'Marketing', 'LV1', '2020-01-01');
INSERT INTO employees(name, salary, department, position, hireDate) VALUES('Clara', 420, 'Sales', 'LV2', '2018-01-11');
INSERT INTO employees(id, name, salary, department, position, hireDate) VALUES(3, 'Jane', 620, 'Developer', 'LV4', '2015-11-01');
--전체 필드에 빠짐없이 값을 넣을 시 필드명 생략 가능
INSERT INTO employees VALUES(4, 'Peter', 530, 'Developer', 'LV2', '2020-11-01');
"""
cur.executescript(script) #여러 SQL 명령어를 한 번에 실행
conn.commit() #connect -> commit/rollback -> close, DB에 위 Table & Data를 저장- 위의 코드의 경우 script안에 drop table~, create table~, insert into~의 여러 명령어가 있기 때문에 `cur.executescript`를 사용했다. 데이터는 `insert into 테이블명 (컬럼들), values (값들);`로 넣어준다.
cur.execute("SELECT * FROM employees;") #이것만으로는 뭐 나오지 않음
cur.fetchone() #첫번째 행 꺼내기 #(1, 'Dave', 300.0, 'Marketing', 'LV1', '2020-01-01')
cur.fetchall() #전체 행 꺼내기
- 바로 위에서 `cur.fetchone()`으로 첫번째 행을 꺼냈기에 2, 3, 4번째 행만 꺼내졌음을 알 수 있다.
data = [('Elena', 510, 'Recruiter', 'LV3', '2020-07-01'),
('Sujan', 710, 'HR', 'LV5', '2014-06-01'),
('Jake', 210, 'CEO', 'LV8', '2012-01-01')]
cur.executemany("INSERT INTO employees(name, salary, department, position, hireDate) VALUES(?, ?, ?, ?, ?);", data)
#구조가 동일한 하나의 sql문을 여러 번 실행해줌
conn.commit() #elena, sujan, jake의 데이터까지 저장
cur.execute("SELECT * FROM employees;") #employees의 모든 데이터 선택
employee_list = cur.fetchall() #전체 꺼내서 employee_list에 저장
employee_list
- `cur.executemany(sql명령어, 파이썬 리스트 등)`는 리스트를 명령어에 넣어 알아서 실행해주는 것 같다.. 신기하다. 참고로 employee_list에 employees의 데이터들을 할당해 준 만큼 [employee for employee in employee_list]로도 위와 같은 값을 출력할 수 있다.
import pandas as pd
df = pd.read_sql_query("SELECT * FROM employees;", conn)
#conn(연결되어 있는 거)를 employees라고 보고 df에 할당
df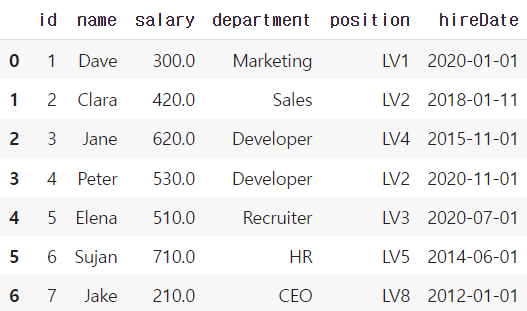
- 사용한 후에는 항상 conn.close()로 연결을 끊어주자
DDL(Data Definition Language): 데이터 정의 언어
- 각 릴레이션(DB테이블)을 정의를 위해 사용하는 언어. CREATE, ALTER, DROP이 있다.
import pandas as pd; import sqlite3
dbpath = "maindb_2.db" #db파일 불러오기 혹은 만들어주기
conn = sqlite3.connect(dbpath) #연결
cur = conn.cursor() #커서 생성
script = """
CREATE TABLE contacts (
contact_id INTEGER PRIMARY KEY,
likes INTEGER DEFAULT 0, --값을 입력하지 않으면 디폴트값 0
first_name TEXT NOT NULL,
last_name TEXT NOT NULL,
email TEXT NOT NULL UNIQUE, --값들은 유일해야 함(중복일 경우 에러 발생)
phone TEXT NOT NULL UNIQUE CHECK (length(phone) >= 10) --길이가 10이상이어야 함(미만일 경우 에러 발생)
);
""" #필드 생성 후에 `PRIMARY KEY(필드명)`로 primary key를 지정해 줄 수도 있음
cur.execute(script) #<sqlite3.Cursor at 0x7fa16a9f3500>
script = """SELECT * FROM contacts;""" #contacts테이블 전체를 선택한 것을 script에 지정
df = pd.read_sql_query(script, conn) #연결된 것을 script에 넘겨 읽음
df
- 위의 employees테이블처럼 values를 주지 않았기에 필드(컬럼)들만 있는 모습이다.
- Primary key는 테이블을 구분짓는 핵심 필드. 두 개로 설정할 수도 있다(`PRIMARY KEY (a, b)`: a필드와 b필드 둘 다 primary key가 됨)
- Foreign key라고 해서 다른 테이블(A라 가정)의 필드(a라 가정)를 참조해 새로운 필드를 생성할 수도, A테이블의 a필드와 연동시켜 a필드에 변동이 있을 시(삭제 등) 똑같이 변동시킬 수도 있다.
SQL CRUD - Simple CRUD: DML(Data Manipulation Language), 데이터 조작 언어
- 데이터 관리(CRUD)를 위한 언어. CRUD는 INSERT(Create), SELECT(Read), UPDATE, DELETE의 약자.
import sqlite3
dbpath = "chinook.db"
conn = sqlite3.connect(dbpath)
cur = conn.cursor()
cur.execute("SELECT 10/5, 2*4;")
result = cur.fetchall() #SQL 실행 결과 "모두"얻어오기
print(result) #[(2, 8)] #이런 식으로 계산기로 사용도 가능- 아래는 순서대로 INSERT(Create)와 SELECT(Read), UPDATE, DELETE의 쿼리 예시.
script = """
INSERT INTO artists (name)
VALUES ('Bud Powell');
""" #artists 테이블에(into) 새로운 값(VALUES)을 삽입(insert)
cur.execute(script) #위 명령어 실행
script = """
SELECT ArtistId, Name
FROM Artists
ORDER BY ArtistId DESC;
--새로 넣어준 건 마지막에 있음: 내림차순으로 정렬해 확인(혹은 df.tail()로 확인)
""" #artists테이블에서 ArtistId와 Name필드를 가져와 ArtistId 내림차순으로 정렬
cur.execute(script) #위 명령어 실행script = """
INSERT INTO artists (name)
VALUES ("Buddy Rich"), ("Candido"), ("Charlie Byrd");
""" #이렇게 여러 레코드(행)들을 병렬로 담아 동시에 삽입시켜 줄 수도 있다.
cur.execute(script) #명령어 실행
script = """
SELECT employeeid, firstname, lastname, title, email
FROM employees;
""" #employees테이블에서 employeeid, firstname, lastname, title, email필드만 가져오기
cur.execute(script) #명령어 실행script = """
UPDATE employees
SET lastname = 'Smith'
WHERE employeeid = 3;
""" #employees테이블에서 employeeid가 3인 레코드를 찾아 lastname을 smith로 설정(SET)
cur.execute(script) #명령어 실행
script = """
UPDATE employees
SET city = 'Toronto', state = 'ON', postalcode = 'M5P 2N7'
WHERE employeeid = 4;
""" #이렇게 여러 필드값을 동시에 설정(SET)해 주는 것도 가능
cur.execute(script) #명령어 실행
script = """
UPDATE employees
SET email = UPPER(firstname || "." || lastname || "@chinookcorp.co.kr");
--||: SQLite에서 문자열 간의 더하기(concatenate)
""" #테이블의 모든 레코드에 대하여(=WHERE문 X) email필드값을 대문자(성.이름@chinook~)로 설정(SET)
cur.execute(script) #명령어 실행script = """
DELETE FROM employees
WHERE employeeid = 2;
""" #SELECT는 SELECT * FROM ~으로 썼지만 DELETE는 DELETE FROM으로 씀
#employeeid가 2인 레코드를 찾아 employees테이블에서 삭제
cur.execute(script) #명령어 실행- `conn.rollback()`으로 마지막 `commit()`(저장) 시점 이후의 수정 사항을 전부 취소시킬 수 있다.
- SQLite에서 None(결측치)은 가장 작은 값으로 인식되므로 오름차순 정렬을 했을 때 맨 위(앞)에 위치한다.
script = """
SELECT DISTINCT city
FROM customers
ORDER BY city;
""" #구별되는 city값들(=중복이 없는)만 선택하여 city값에따라 정렬
df = pd.read_sql_query(script, conn) #현재 연결된 db에 script명령어를 읽게함(실행)
#널도 하나의 데이터로 인식하므로 결측치 또한 하나만 남게 됨
script = """
SELECT DISTINCT city, country
FROM customers
ORDER BY country;
""" #이 경우 city와 country 두 필드 모두에서 값이 동일해야 중복으로 제거됨
df = pd.read_sql_query(script, conn) #연결된 db에 script명령어 읽게 함(실행)script = """
SELECT name, milliseconds, bytes, albumid
FROM tracks
WHERE albumid = 10;
""" #WHERE뒤에는 조건절을 씀. 같다는 =, 다르다는 <>.
df = pd.read_sql_query(script, conn) #실행 시 df에는 albumid가 10인 레코드만 있음
script = """
SELECT name, milliseconds, bytes, albumid
FROM tracks
WHERE (albumid = 10) AND (milliseconds > 250000);
""" #두 조건을 모두 만족시키는 레코드들만 선택
df = pd.read_sql_query(script, conn) #연결된 db에 sql명령어 실행
script = """
SELECT name, albumid, mediatypeid
FROM tracks
WHERE mediatypeid IN (4, 5);
""" #mediatypeid가 4나 5에 속하는 레코드 선택
df = pd.read_sql_query(script, conn)- WHERE에 조건으로 사용할 수 있는 연산자로는 비교(=, <>, <, <=, >, >=), 범위(BETWEEN, NOT BETWEEN), 집합(IN, NOT IN), 패턴(LIKE, NOT LIKE), 결측치(IS NULL, IS NOT NULL), 복합조건(AND, OR, NOT)이 있다.
- 문자열 와일드카드
- %: 0개 이상의 문자열과 일치:: '%metamon%'은 metamon을 포함하고 앞뒤에 문자열 0개 이상 있어야
- []: 1개의 문자와 일치:: '[0-8]%'는 0-8중의 숫자 하나로 시작하는 문자열
- [^]: 1개의 문자와 불일치:: '[^0-9]%'는 0-9중의 숫자 하나로 시작하지 않는 문자열
- _: 특정 위치의 1개 문자와 일치:: '%met_%'는 met뒤에 1개의 문자열이 존재하는 문자열
- +: 문자열 연결:: 'meta'+'mon'은 'meta mon'
script = """
SELECT trackid, name
FROM tracks
WHERE name LIKE 'Wild%';
""" #name필드 값이 wild로 시작하고('Wild') 뒤에 0개 이상의 문자열이 있는('%') 레코드 선택
df = pd.read_sql_query(script, conn) #연결된 db에 script명령어를 읽게 함(실행)
script = """
SELECT trackid, name
FROM tracks
WHERE name LIKE '%Br_wn%';
""" #tracks테이블에서 name이 'Br과 wn사이에 문자 1개가 위치한 값'인 것의 trackid, name 가져오기
#Brown, Br1wn, Brywn, 등 어떤 문자든 _자리에 있으면 됨
df = pd.read_sql_query(script, conn) #연결된 db에 sql명령어 실행script = """
SELECT TrackId, Name, AlbumId
FROM Tracks
WHERE AlbumId IN (SELECT Albumid FROM Albums WHERE ArtistId=12);
""" #AlbumId가 'Albums테이블에서 ArtistId가 12인 레코드의 AlbumId'인 레코드 선택
df = pd.read_sql_query(script, conn) #연결된 db에 sql명령어 실행
script = """
SELECT trackId, name
FROM tracks LIMIT 10 OFFSET 7;
""" #OFFSET만큼을 떼어내고 LIMIT만큼만 선택(인덱스 8번부터 17까지)
df = pd.read_sql_query(script, conn)https://school.programmers.co.kr/learn/courses/30/lessons/77484?language=python3
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
def solution(lottos, win_nums): #구매한 로또번호 lottos, 당첨번호 win_nums
answer=[]; same=0; diff=0; zeros=0
for num in lottos:
if num in win_nums: #구매한 로또 번호가 당첨번호에 해당하는 게 있다면
same += 1
elif num == 0: #구매한 로또 번호가 알아볼 수 없는 상태라면
zeros += 1
else: #구매한 로또 번호가 당첨번호에 해당하지 않는다면
diff += 1
aa = same + zeros #aa는 맞출 수 있는 최고 개수
if aa == 6: #모두 다 맞추었다면 1등
answer.append(1)
elif aa <= 1: #1개 이하로 맞추었다면 6등
answer.append(6)
else: #2개부터 5등, 3개 4등,... 5개 2등
answer.append(7-aa)
bb = zeros + diff #bb는 맞출 수 없는 최고 개수
if bb == 6: #모두 다 맞추지 못했다면 6등
answer.append(6)
elif bb == 0: #모두 다 맞추었다면 1등
answer.append(1)
else: #5개 맞추지 못한 경우 6등, ... 1개 맞추지 못한경우 2등
answer.append(bb+1)
return answer #[최고순위, 최저순위]이번에도 역시나 이렇게 길고 허접한 코드가 제 코드구요.. ㅎㅎㅎ
def solution(lottos, win_nums):
rank = [6,6,5,4,3,2,1]
cnt_0 = lottos.count(0)
ans = 0
for x in win_nums:
if x in lottos:
ans += 1
return rank[cnt_0 + ans],rank[ans]이게 다른 분들의 코드인데... 우와, 1분만에 감탄했습니다.
랭크라는 리스트를 만들고, 0의 개수를 세고(cnt_0), 정답 개수를 세서 인덱스로 활용... 한다니 진짜 천잰가요..? 다른 분들도 댓글에서 박수 열번 쳤다고 진짜 천재같다고 칭찬하시던데 인정.. 인정이요!!
프로그래머스 문제 두개 풀고 싶었는데 생각보다 위 문제에 시간을 너무 오래 써서ㅠㅠ(same, diff, zeros를 처음부터 고안한 게 아니라 여러 번의 시행착오 끝에 채택하였읍니다... 1단계 문제를 두시간~두시간 반 정도 걸려서 풀었어요..^ㅠ^...) 다음엔 시간을 더 두고 여유롭게.. 하고싶네요...
'STUDY' 카테고리의 다른 글
| 파이썬 스터디 ver3. 8주차 (2) | 2022.08.22 |
|---|---|
| 파이썬 스터디 ver3. 7주차 (2) | 2022.08.14 |
| 파이썬 스터디 ver3. 5주차 (0) | 2022.07.30 |
| 파이썬 스터디 ver3. 4주차 (1) | 2022.07.24 |
| 파이썬 스터디 ver3. 3주차 (0) | 2022.07.14 |



