2022.08.01~2022.08.05
구름 X 전주 ict 이노베이션스퀘어의 온라인 코딩교육 내용을 정리하였습니다.
저번주에 SQL 관련 내용들을 거의 다 정리하였다고 보고, 나머지 SQL 내용은 생략하고 ML부터 시작합니다~
인공지능Artificial Intelligence: 목표 성취의 가능성을 최대화 하도록 만든 (기계의)지능.
학습Learning: 데이터를 가장 잘 설명하는 모델을 찾는 방법. Model fitting 과정이라고도 함.
- 이를 위해 1)초기 모델에 데이터를 넣고 2)결과를 평가해 3)결과 개선을 위해 모델을 수정하는 과정을 수행하기도 한다. 주로 결과 개선은 '실제 정답과 예측 결과 사이의 오차'(Loss, Cost, Error)를 줄여나가는 것을 말한다.
ML을 적용한 인공지능 활용은 1)데이터를 활용해 2)알고리즘 후보를 정하고 최적의 파라미터를 설정한 뒤 3)적용시켜 만드는 것을 말한다.
- Machine Learning: 과제 해결 과정에서 "학습"을 해 (특정 평가기준으로 측정한)성능을 향상시킬 수 있는 프로그램.
- 크게 지도학습(Supervised Learning), 비지도학습(Unsupervised Learning), 강화학습(Reinforcement Learning)으로 나뉨. 지도/반지도는 데이터에 정답(Target 혹은 Label)이 존재하는지에 따라 나뉘고, 강화는 여러 번의 시도를 통해 최적의 보상을 받을 수 있는 방법을 배워나감.
- iris, titanic데이터로 무엇이 setosa고 어떤 사람이 생존할 것인지 예측하는 것: 지도학습, 기저귀를 사는 사람 중에서는 맥주를 사는 사람들이 많다는 것: 비지도학습, 알파고가 바둑을 배워 이세돌을 이긴 것: 강화학습.
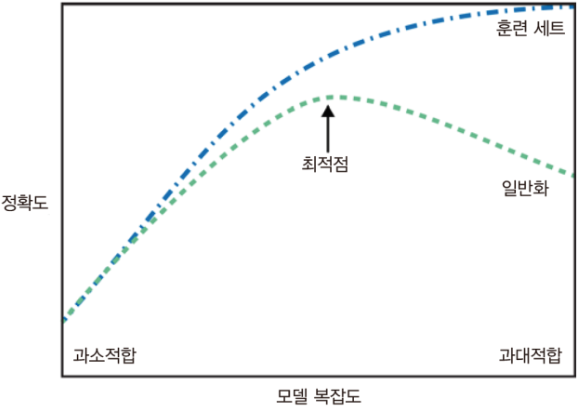
모델 복잡도Model's capacity
- 복잡도가 높아 과적합(Over fitting)될 경우 훈련 데이터에만 최적화되어있어 1)모델이 복잡하고 2)테스트 데이터나 타 데이터에 대해 일반화하기가 어렵다
- 복잡도가 낮아 과소적합(Under fitting)될 경우 제대로 된 모델학습이 되지않아 예측의 정확도를 높이기 힘들다.
데이터를 나누는 방법들
- CV(Cross Validation): 교차검증. 전체 데이터를 60/20/20의 세 그룹(학습데이터/검증데이터/테스트데이터)으로 나누는 것. 참고로 검증데이터는 모델/하이퍼파라미터 선택/최적화에 쓴다. 데이터 크기에 따라 다르긴 하지만, 주로 검증 데이터를 제외한 학습/테스트의 7:3, 8:2를 많이 쓰는 듯 하다.
- (Stratified)K-Fold CV: 여기서 K는 폴드 수. 학습데이터를 K만큼 나누고 하나(1/K)를 검증 데이터, 나머지를 학습 데이터로 학습-채점을 반복하면서 나온 값들의 평균을 모델 값으로 가진다. 가장 높은 점수를 기록한 모델을 사용한다.
학습률: learning rate. 말그대로 (모델이)얼마나 학습해갈지(얼마나 '움직일지')를 결정함. hyper-parameter의 일종.
- 하이퍼파라미터: 사람이 값을 설정해 주어야 하는 것. 반면 파라미터는 컴퓨터가 알아서 정하는 것.
선형회귀Linear Regression
- 종속변수 y와 (한 개 이상의)독립(설명)변수 x의 선형관계를 모델링하는 회귀분석 기법.
- `y=ax+b`일때 a를 가중치, b를 오류(혹은 편향)라고 함. x가 1개면 단순 회귀, x가 2개 이상이면 다중 회귀.
- Cost function: 비용함수. '예측값과 실제값의 차이'로 모델 성능을 판단하는 데 사용됨. 선형회귀의 경우에는 Mean Squared Error(MSE, 평균제곱오차) 사용. 이는 오차제곱합의 평균. 다시말해 선형회귀는 MSE를 최소로 만드는 파라미터를 찾는 것
경사하강Gradient Descent
- 경사Gradient: 변수의 편미분(=기울기)을 벡터로 정리한 것.
- 변수 초기값 설정 > 현재 변수값에 대응되는 비용함수 경사도 계산 > 경사 따라가며 다음 변수값 설정 > 비용함수가 최소가 될 때(=값이 변하지 않거나 매우 느리게 변할 때) 까지 반복

K-최근접이웃 K-Nearest Neighbors
- 새 데이터와 가장 가까운 (훈련)데이터를 찾아 새 데이터가 무엇에 해당할 지 판단하는 것. K값에 따라 '가깝다'고 볼 이웃 데이터 수가 결정됨
- 매개변수로 거리계산법, 이웃 수를 받음. 거리계산은 주로 유클리디안 거리 사용. 유클리디안 거리는 p(p1, p2)와 q(q1, q2)의 거리를 sqrt( (p1-q1)^2, (p2-q2)^2 )로 구하는 것.
- 거리를 계산하기때문에 정규화 과정이 필요함!
Scikit-learn
- 파이썬으로 ML알고리즘들을 구현한 오픈소스 라이브러리. numpy, pandas, matplotlib등과 호환이 잘 됨
from sklearn import datasets, model_selection, linear_model
from sklearn.metrics import mean_squared_error
iris = datasets.load_iris() #데이터 불러오고 훈련/테스트 데이터로 나누기
X_train, X_test, y_train, y_test = model_selection.train_test_split(iris.data,iris.target, test_size=0.3)
model = linear_model.LinearRegression() #선형회귀 모델 만들기
model.fit(X_train, y_train) #train데이터 학습시키기
print(mean_squared_error(model.predict(X_test), y_test)) #x예측데이터와 실제 데이터의 mse비교 #0.034- 크게는 (0. 데이터 분리) 1.모델 생성, (하이퍼)파라미터 조정 2.모델 학습 3.예측, 평가의 순서를 가짐.
https://school.programmers.co.kr/learn/courses/30/lessons/92334
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
def solution(id_list, report, k):
lst = []; ans = []; answer = [];
report = set(report)
for i in report: #신고명단 받아 나누기
_, name = i.split(' ')
lst.append(name)
for x in id_list:
if lst.count(x) >= k:
ans.append(x) #k번 이상 신고당한 목록
for y in id_list:
temp = 0 #받을 정지 통보 메일 개수
for z in ans:
if y + " " + z in report:
temp += 1
answer.append(temp) #id_list의 순서대로 append
return answer자 일단 문제 이해만 2~30분 정도 걸렸구요.. 특정 과정에서 막혀서 해결하는 데만 1시간 15분 정도 걸렸고, 어떻게 돌아가는지 이해하고 조금이나마 더 수월하게 만들어보고자 노력하는 데에만 15분 정도 걸렸습니다.
^^.. 그 결과가 저렇게 허접한 코드라니 참 슬프죠..? 근데 저는 정말 어떻게 해야 조금이나마 더 효율적인 코드를 짤 수 있을지 모르겠는걸요... 자 이제 다른 분들의 코드를 보고오게씁니다
def solution(id_list, report, k):
answer = [0] * len(id_list)
reports = {x : 0 for x in id_list}
for r in set(report):
reports[r.split()[1]] += 1
for r in set(report):
if reports[r.split()[1]] >= k:
answer[id_list.index(r.split()[0])] += 1
return answerreport부분에 set을 쓴 뒤 split하신 부분은 동일한데 나머진 다 다른 것 같네요..!
우선 answer를 0으로만 이루어진 길이 id_list와 동일한 리스트라 보셨고, reports는 id_list개수만큼의 딕셔너리로 보셨어요. 첫번째 for문에서는 reports에 '신고받은 id'에 해당하는 id의 카운트를 올려주었고 두번째 for문에서는 k번 이상 신고당한 id들에 한해 answer에서 id_list내의 ('신고한 id')인덱스를 찾아 1을 더해줬습니다.
뭔가.. 여러 개념을 한번에 활용하신 듯한 느낌이네요. 인덱스 부분은 좀 어지럽구..ㅋㅋㅋ
딕셔너리 정도는 저도 활용할 수 있었을 것 같긴 한데.. 활용할 수 있을 거란 생각을 아예 못 했어요 ㅠ-ㅠ
https://school.programmers.co.kr/learn/courses/30/lessons/81301
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
def solution(s):
dicts = {'zero':0, 'one':1, 'two':2,
'three':3, 'four':4, 'five':5,
'six':6, 'seven':7, 'eight':8, 'nine':9} #영단어를 숫자로
for i in dicts: #dicts중에 해당되는 게 있는지 확인
if i in s: #해당되는 게 있다면
s = s.replace(i, str(dicts[i])) #해당값을 밸류값으로 repalce
answer = int(s) #int형으로 변경
return answer이번에는 정규표현식을 한번 써볼까, 아니면 당장 떠오르는 딕셔너리 방식으로 풀어볼까...
정규표현식으로 풀어보려다가(`re.sub('[z%]', 0, s)`를 0부터 9까지 만들어서...) 안되길래 때려쳤습니다 ^-^ 그래도 나름 괜찮게 풀었다고 생각하는데 아닐까요..?
다른 분들 코드도 보겠습니다!
num_dic = {"zero":"0", "one":"1", "two":"2", "three":"3", "four":"4",
"five":"5", "six":"6", "seven":"7", "eight":"8", "nine":"9"}
def solution(s):
answer = s
for key, value in num_dic.items():
answer = answer.replace(key, value)
return int(answer)딕셔너리로 푼 건 동일한데 오.. items..! items로 key랑 value 둘 다를 빼서 제가 replace부분에 i, dicts[i]를 쓸 때 key랑 value를 써주셨네요! 그이후는 동일하구요. int씌우기는..ㅠㅠ 다음엔 저렇게 해봐야겠어용..
def solution(s):
words = ['zero', 'one', 'two', 'three', 'four', 'five', 'six', 'seven', 'eight', 'nine']
for i in range(len(words)):
s = s.replace(words[i], str(i))
return int(s)이건 다른 풀이입니다. 개인적으로는 바로 위의 코드보다 이게 더 좋은 것 같아요!
words의 개수만큼 for문을 돌리는데(=dict개수만큼 for문을 돌림), i번째 요소가 s 안에 존재한다면 그를 str(i), 즉 그 인덱스 번호로 바꿔주는거죠! 적어도 제 눈에는 이게 제일 효율적으로 보여요!
https://school.programmers.co.kr/learn/courses/30/lessons/86051
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
num_lst = list(range(0, 10)) #0부터 9까지의 숫자가 들어있는 리스트
def solution(numbers):
ans = 0
for nums in num_lst:
if nums not in numbers: #0부터 9 중 매개변수 numbers에 없는 게 있다면
ans += nums #ans에 더해주기
return ans음.. ㅇㅅㅇ 뭐지 싶은 문제...입니다. 응? 설마 이렇게 풀리는 건가? 했는데 네 진짜네요.. 당황스러울 뿐 ㅇㅅㅇ
아 그와중에 num_list 따로 만들지 말고 그냥 range 쓸걸...ㅠㅠ
def solution(numbers):
return 45 - sum(numbers)와
아니 잠깐만ㅋㅋㅋㅋ 아 와ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ 아ㅋㅋㅋ 오ㅋㅋㅋㅋ 우와ㅋㅋㅋㅋㅋ 대박.. 발상의 전환...!!!
없는거 더하라 그래서 숫자리스트 만들고 not in으로 더해주고 있었는데 이분은 그냥 0부터 9까지의 합-받은 숫자 합으로 한번에 푸셨네요.. 진짜 대박이다 와... 아니 쉬운 문제라고 '응? 이거머임?ㅋㅋ' 하고 있을 때가 아니었네요.... ㄷㄷㄷ
https://school.programmers.co.kr/learn/courses/30/lessons/42576
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
def solution(participant, completion):
for i in participant:
if completion.count(i) != participant.count(i):
return i #completion과 participant에서의 개수가 다르다면 반환제 블로그 글을 몇 개 보신 분이라면 아시겠지만, 전 중간 과정의 코드를 잘 정리하지 않습니다.
다만 이건 정리할 필요가 있겠다 싶어서 적어봐요. 위는 최종코드가 아닌, '정확성'에서만 통과하고 '효율성'은 통과하지 못한 코드입니다. 다..만.... dict로도 풀어보려 했지만 도무지 어떻게 해야하는지 감이 잡히지 않아 좌절하고 힌트가 될 만한 것을 찾아 '질문하기'를 보다 겨우 발견한 게 아래입니다.
def solution(participant, completion):
participant.sort(); completion.sort(); answer=''
for i in range(0, len(completion)):
if participant[i] != completion[i]:
answer = participant[i]
break
return answersort로 요소들을 정리해 준 뒤 두 리스트의 요소값을 비교하여 같지 않다면 바로 break를 걸어 시간을 단축하셨습니다. 역시 제 페인은 counter를 쓰고싶다, 혹은 dict로 개수를 세야겠다는 믿음이었을까요..?
import collections
def solution(participant, completion):
answer = collections.Counter(participant) - collections.Counter(completion)
return list(answer)[0]이건 많은 추천을 받은 풀이입니다. 아예 collections라이브러리를 가져와서 사용하셨는데.. 아, 빼기가 가능하다는 건 처음 알았어요.. 아니 알고있었나..? ㅎ.. 뭐 못 떠올렸으면 모르고 있었다고 봐도 문제 없지 않을까요...
어쨌든 제가 그렇게도 쓰고싶었던 counter를 쓰셔서 participant의 개수와 completion에서의 개수를 빼고('개수'라고 표현했지만 두 수가 같다면 아예 사라지는 것처럼 보입니다. 가령 Counter({'metamon':1}) - Counter({'metamon':1})은 공백이 남아있습니다.) 남아있는 counter의 이름'만' 가져오기 위해 리스트로 만들어 준 뒤 첫 번째 요소(0번째 인덱스)만 빼옵니다.
이게 모듈을 배워야 하는 이유인가봐요.. 정말 대단합니다. collections와 counter를 알고있었어도 counter끼리 빼기가 된다는 걸 알아야 저런 활용이 가능하니까요...ㅠㅜ
https://school.programmers.co.kr/learn/courses/30/lessons/76501
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
def solution(absolutes, signs):
answer = []
signs = [1 if signs[i]==True else -1 for i in range(len(signs))]
answer = [absolutes[i] * signs[i] for i in range(len(absolutes))]
return sum(answer)평소처럼 for문, if문으로 풀다가 리스트 컴프리헨션으로 써봐도 좋을 것 같아 이렇게 썼습니다!
사실 리스트 컴프리헨션을 몇 번 사용해보질 않아서, 연습 겸 문법 한 번 찾아본 뒤 활용해서 풀었습니다.
더 짧은 코드들도 있긴 하지만 저는 제 코드가 제일 마음에 들어요. 바퀴벌레도 자기 자식은 예쁘다고 생각하는 느낌.. :3
'STUDY' 카테고리의 다른 글
| 파이썬 스터디 ver3. 9주차 (3) | 2022.08.26 |
|---|---|
| 파이썬 스터디 ver3. 8주차 (2) | 2022.08.22 |
| 파이썬 스터디 ver3. 6주차 (3) | 2022.08.06 |
| 파이썬 스터디 ver3. 5주차 (0) | 2022.07.30 |
| 파이썬 스터디 ver3. 4주차 (1) | 2022.07.24 |



