2022.08.08~2022.08.12
구름 X 전주 ict 이노베이션 스퀘어의 온라인 코딩교육 내용을 정리하였습니다.
저번 주에 이어서 ML 정리 해보도록 하겠습니다!
KNN(이어서)
- 결정경계: 이웃 수가 적을수록 경계선은 복잡해지며(복잡도 상승), 많아질수록 경계선은 부드러워짐(복잡도 하락).
- KNN 회귀: 여러 최근접 이웃 사용 시, 이웃 간 평균으로 예측하는 것. (연속적인 값인)데이터의 평균 유사도로 판단.
x_train = np.array([
[0.5, 0.2, 0.1],
[0.9, 0.7, 0.3],
[0.4, 0.5, 0.7]
]) #데이터
y_train = [5.0, 6.8, 9.0] #타겟값
model = KNeighborsRegressor(n_neighbors=3, weights='distance') #거리에 가중치
model.fit(x_train, y_train) #모델 학습
x_test = np.array([[0.2, 0.1, 0.7], [0.4, 0.7, 0.6], [0.5, 0.8, 0.1]])
#예측할 데이터
model.predict(x_test) #각각 7.28, 7.76, 6.84로 예측
결정트리Decision Tree
- 분류, 회귀 모두에 사용. 분할Split과 가지치기Pruning가 포인트. 데이터 정규화, 널값처리가 크게 필요하지 않음.
- 가지치기: (하이퍼 파라미터 max_depth 설정 등으로)트리의 성장을 막는 것.
- 학습 데이터로 조건을 만들고 훈련 데이터가 리프 노드(끝 노드)에 도달하면 결과를 냄.
- 트리 기반의 다양한 앙상블Ensemble모델이 존재.
- 트리 구조: 노드node로 이루어진 자료구조, 계층모델. 그래프의 한 종류.
- 비선형 데이터, 모델 해석, 시각화에 좋으나 선형 데이터, 데이터 변화, 적은 데이터 수, 고르지 못한 데이터 분포의 경우 좋지 않은 성능을 보임.
from sklearn.tree import DecisionTreeClassifier #트리 분류기
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt; from sklearn import tree
iris =load_iris() #아이리스 데이터 사용
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target,
test_size=0.2, random_state=11)
model = DecisionTreeClassifier().fit(x_train, y_train) #모델 만들기+학습
print(model.score(x_train, y_train), model.score(x_test, y_test)) #(1.0, 0.9333333)
plt.figure(figsize=(20, 15))
tree.plot_tree(model, class_names=iris.target_names, feature_names=iris.feature_names,
filled=True, impurity=False, rounded=True)
plt.show() #맷플롯립을 사용한 트리 그래프 시각화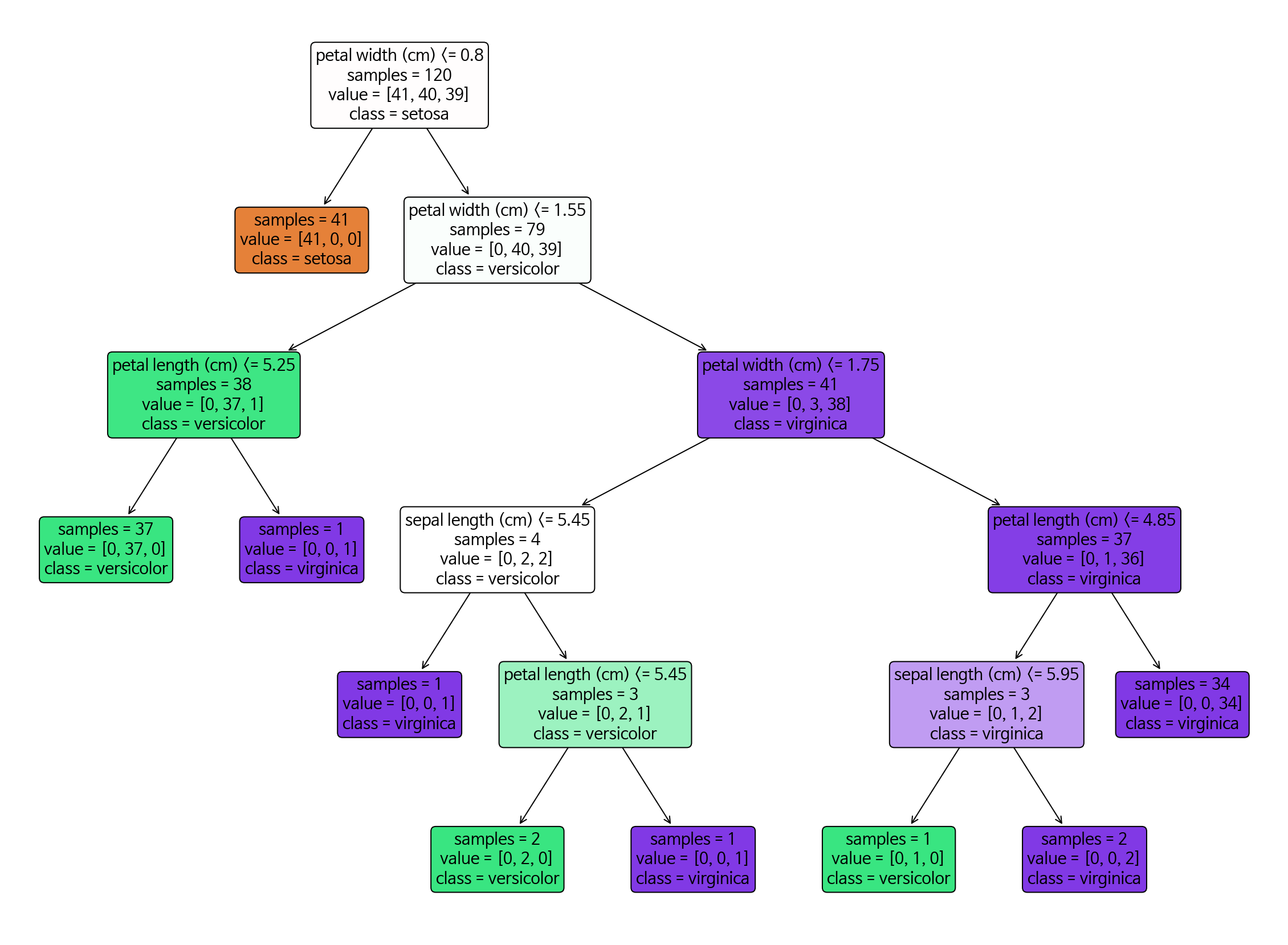
- 규칙에 따라 브랜치branch노드와 리프leaf노드가 구성됨. 데이터의 '흐름'을 찾는 것이 중요
- 하이퍼 파라미터로 `min_samples_split`(sample이 최소 몇 개 이상일 때 나눌 것인지), `min_samples_leaf`(리프 노드의 sample이 최소 몇 개 이상이어야 하는지), `max_depth`(tree의 최대 깊이를 몇으로 둘 건지)등을 설정할 수 있다. 이들 설정으로 과적합을 막아줄 수 있음.
- `tree모델.feature_importances_`로 어떤 특성feature이 트리 (규칙)생성에 얼마나 기여했는지를 알 수 있다.
print("트리 특성 중요도:", np.round(model.feature_importances_, 3))
#트리 특성 중요도: [0. 0. 0.026 0.974] #sepal length, sepal width, petal length, petal width- 불순도impurity(혹은 엔트로피entropy, 지니계수gini coefficient) 기준으로 최대한 같은 것들끼리 모이도록(불순도가 낮도록) 학습
from sklearn.tree import DecisionTreeRegressor #트리 회귀
from sklearn.linear_model import LinearRegression
import os; import mglearn
import matplotlib.pyplot as plt
%matplotlib inline
df = pd.read_csv(os.path.join(mglearn.datasets.DATA_PATH, "ram_price.csv"))
d_train = df[df['date'] < 2000]; d_test = df[df['date'] >= 2000]
#2000년 이전 데이터를 d_train, 2000년 이후 데이터를 d_test로 만듦
X_train = d_train.date[:, np.newaxis] #d_train의 날짜에 대해서만 2차원으로 만듦
print(X_train.shape) #(202, 1)
y_train = np.log(d_train['price']) #d_train의 price컬럼 값을 로그스케일로 변경
model_tree = DecisionTreeRegressor().fit(X_train, y_train)
model_lr = LinearRegression().fit(X_train, y_train)
#결정트리 회귀, 선형회귀 모델 만들고 '훈련데이터 날짜'와 'price의 로그스케일 값'을 학습시킴
X_test = df.date[:, np.newaxis] #원본 df의 날짜값을 2차원으로 만듦
pred_tree = model_tree.predict(X_test) #(원본 df의)전체 기간에 대해 tree로 예측
pred_lr = model_lr.predict(X_test) #(원본 df의)전체 기간에 대해 선형회귀로 예측
pred_tree = np.exp(pred_tree); pred_lr = np.exp(pred_lr)
#예측한 값의 로그 스케일 되돌리기(로그했던거에 exp씌우면 원본값 됨)
plt.semilogy(d_train['date'], d_train['price'], label='train') #y축에 로그스케일 설정
plt.semilogy(d_test['date'], d_test['price'], label='test')
plt.legend(); plt.show()
plt.semilogy(df['date'], pred_tree, label='Tree')
plt.semilogy(df['date'], pred_lr, label='Linear')
plt.legend(); plt.show() #트리의 경우 2000년 이후 데이터에 대해 예측x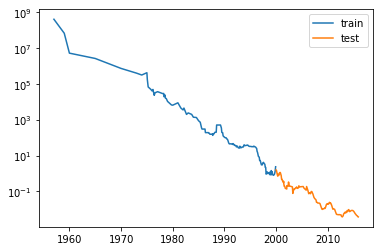
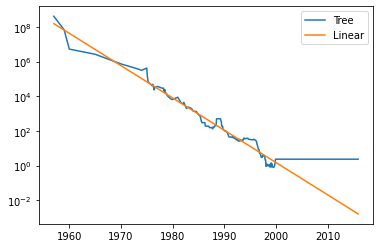
- 트리는 train 데이터 범위 안에서만 예측 가능(2000년 전인 train데이터에 대해서는 어느정도 잘 예측하는 듯 하나, 2000년 이후인 test데이터에 대해서는 예측을 수행하지 못함)
- 트리 회귀에서는 각 분할이 MSE(Mean Squared Error, 평균제곱오차)를 최소화 하도록 함
앙상블Ensemble
- 여러 모델을 연결해 더 나은 모델을 만드는 것. 주로 트리 기반인 'Random Forest'와 'Gradient Boosting' 사용.
- 보팅, 배깅, 부스팅의 세 유형으로 나뉨.
import pandas as pd
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
cancer = load_breast_cancer() #유방암 데이터셋 사용
df = pd.DataFrame(cancer.data, columns=cancer.feature_names)
x = cancer.data; y = cancer.target
X_train, X_test, y_train, y_test = train_test_split(x, y, random_state=0, test_size=0.2)
#아래 세 개 모델로 보팅 분류기 만들 예정!
model_lr = LogisticRegression() #로지스틱 회귀
model_knn = KNeighborsClassifier(n_neighbors=8) #KNN 이웃 수: 8개
model_tr = DecisionTreeClassifier(max_depth=4, random_state=0) #결정트리 최대깊이: 4
model_voting = VotingClassifier(estimators=[('LogisticRegression', model_lr),
('KNeighborsClassifier', model_knn),
('DecisionTreeClassifier', model_tr)],
voting='soft') #사용할 모델 명과 모델, 보팅 종류
model_voting.fit(X_train, y_train) #보팅모델 학습 후
print(model_voting.score(X_train, y_train), model_voting.score(X_test, y_test)) #score 확인
#(0.9758241758241758, 0.956140350877193)
for model in [model_lr, model_knn, model_tr]: #각 모델들에 대한 for문
model.fit(X_train, y_train) #데이터 학습시킨 뒤
print(model.__class__.__name__,
model.score(X_train, y_train), model.score(X_test, y_test))
#model의 class name, 학습데이터/테스트 데이터 score 출력
#LogisticRegression 0.9494505494505494 0.9473684210526315
#KNeighborsClassifier 0.9384615384615385 0.9473684210526315
#DecisionTreeClassifier 0.9846153846153847 0.956140350877193보팅Voting: 서로 다른 알고리즘 결합. 일반적으로는 개별 모델 정확도보다 보팅의 정확도가 조금 더 높음
- 랜덤 포레스트: 다수의 트리(Forest)들을 무작위로 학습하는 것. 분류와 회귀 둘 다 가능. 각각의 트리를 사용하는 것보단 더 좋은 결정경계를 만들 수 있게 함.
※OOB(out-of-bag): 샘플링에 중복을 허용하면 평균적으로 63%의 데이터만 샘플링되고 나머지 37%의 데이터는 샘플링되지 않음. 랜덤포레스트에서 `oob_score=True`를 사용하면 63%에 대한 모델 학습 뒤 37%를 활용한 평가를 수행하게 됨.
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt; import mglearn
from sklearn.tree import DecisionTreeClassifier
X, y = make_moons(n_samples=100, noise=0.25, random_state=3) #make_moons 데이터셋 사용
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=42)
model = BaggingClassifier(DecisionTreeClassifier(), n_estimators=5,
n_jobs=-1, random_state=0) #결정트리 기반 배깅
model.fit(X_train, y_train) #배깅모델 학습
print(model.score(X_train, y_train), model.score(X_test, y_test))#0.96 0.88배깅Bagging: 같은 유형 알고리즘을 다르게 샘플링해 학습. train data를 중복을 허용한 랜덤으로 샘플링함.
- 랜덤포레스트는 `DecisionTreeClassifier(splitter='best')`, 배깅은 `DecisionTreeClassifier(splitter='random')`. 랜덤포레스트는 시도들을 아울러 최적의 분할을 해 주고, 배깅은 시도들 중 최적의 분할을 찾는 것:: 시행횟수가 어느 정도를 넘어가면 두 모델의 성능이 비슷해짐
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer() #유방암 데이터
X = cancer.data; y = cancer.target
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
model = GradientBoostingClassifier(n_estimators=100, random_state=0)
model.fit(X_train, y_train) #모델 학습
print(model.score(X_train, y_train), model.score(X_test, y_test)) #1.0 0.9650
#학습데이터에 대해서 과적합(정확도가 1)이니 가지치기 해주자
#max_depth를 줄였을 때
model = GradientBoostingClassifier(n_estimators=100, max_depth=1, random_state=0)
model.fit(X_train, y_train)
print(model.score(X_train, y_train), model.score(X_test, y_test)) #0.9906 0.9720
#learning rate를 줄였을 때
model = GradientBoostingClassifier(n_estimators=100, learning_rate=0.01, random_state=0)
model.fit(X_train, y_train)
print(model.score(X_train, y_train), model.score(X_test, y_test)) #0.9882 0.9650부스팅Boosting: 직전 데이터의 틀린 부분에 가중치weight를 부여하며 학습.
- Gradient Boosting: 여러 약한 학습기(주로 트리)를 묶어 좋은 모델을 만드는 것. 분류와 회귀 둘 다 가능. 깊지 않은 트리들을 직전의 (잔여)오차를 보완하며 순차적으로 만듦
- 보통은 랜덤포레스트를 먼저 쓰고 그라디언트 부스팅을 써준다고 한다!
- 그라디언트 부스팅은 널리 사용되긴 하지만 파라미터에 따라 결과가 적잖이 달라지며 고차원 데이터에는 사용할 수 없다
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt; import mglearn
from sklearn.ensemble import AdaBoostClassifier
X, y = make_moons(n_samples=100, noise=0.25, random_state=3) #two_moon data
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=42)
model = AdaBoostClassifier(n_estimators=5, random_state=0)
model.fit(X_train, y_train) #AdaBoost 모델 만들어서 학습
print(model.score(X_train, y_train), model.score(X_test, y_test)) #0.9066 0.8
fig, axes = plt.subplots(2, 3, figsize=(20, 10))
for tree, ax in zip(model.estimators_, axes.ravel()): #결정경계 시각화
mglearn.plots.plot_tree_partition(X, y, tree, ax=ax)
mglearn.plots.plot_2d_separator(model, X, fill=True, alpha=0.4, ax=axes[-1, -1])
mglearn.discrete_scatter(X[:, 0], X[:, 1], y) #마지막 칸에는 Ada Boost로 만든 결정경계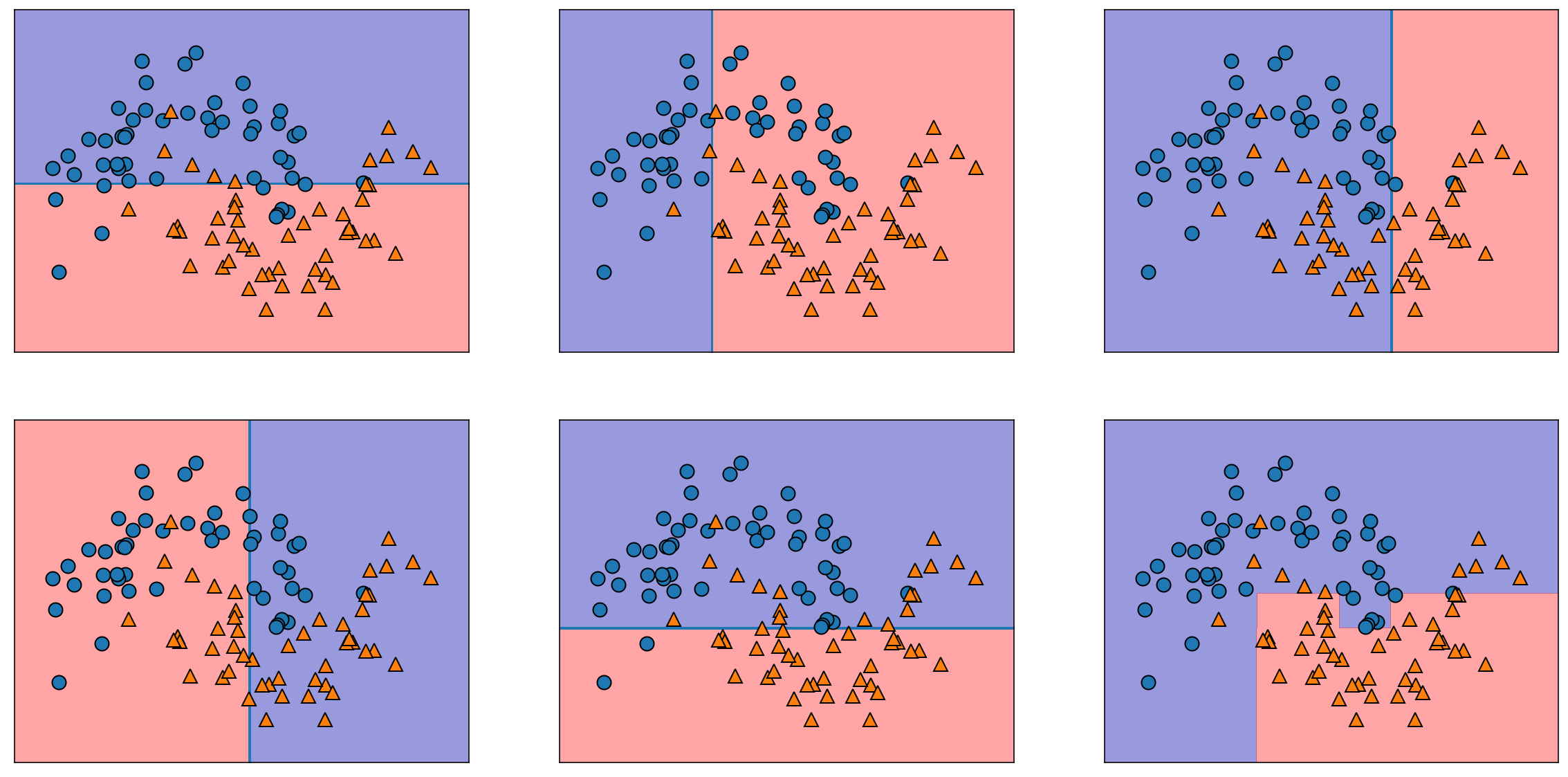
- Ada Boost(Adaptive Boosting): 이전 학습기의 잘못된 '샘플'에 관해 훈련시키는 것. 각 반복마다 샘플의 가중치가 수정됨(성능에 따라 가중치가 부여됨)
- 에이다부스트 분류기는 깊이가 1인 트리를 사용해 각 트리 경계가 직선인 게 특징
from sklearn.model_selection import train_test_split
from xgboost import XGBClassifier; import pandas as pd
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer() #유방암 데이터셋 활용
df = pd.DataFrame(cancer.data, columns=cancer.feature_names)
df['label'] = cancer.target
X = df.iloc[:, :-1]; y = df.iloc[:, -1] #train/test와 데이터/레이블 구분
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
model = XGBClassifier(n_estimators=400, max_depth=3, learning_rate=0.01,
n_jobs=-1, random_state=0)
evals = [(X_test, y_test)] #특성, 타깃 튜플리스트
model.fit(X_train, y_train, eval_set=evals, eval_metric='logloss',
early_stopping_rounds=30) #평가할 데이터(eval_set), 평가 기준(logloss),
#돌리다가 50번 이상 개선이 일어나지 않으면 멈춤(early_stopping_rounds)
#디폴트가 verbose=True이므로 아래처럼 어떻게 진행되었는지를 알 수 있음
# [0] validation_0-logloss:0.685005
# Will train until validation_0-logloss hasn't improved in 30 rounds.
# [1] validation_0-logloss:0.669193 ...
print(model.score(X_train, y_train), model.score(X_test, y_test)) #0.9976 0.9860- XGBoost(eXtreme Gradient Boosting): GBM을 개선해 속도를 높여준 모델. 널값 자체처리가 가능하고 속도가 빠름
- eval_set에는 평가할 데이터를 [(특성, 타깃)] 형태의 튜플 리스트로 전달해 주어야 함. eval_metric에는 평가(측정)지표로, 이진 분류일 때 'logloss' 다중 분류일 때 'mlogloss'.
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier; import pandas as pd
from sklearn.datasets import load_breast_cancer
import seaborn as sns
cancer = load_breast_cancer() #유방암 데이터 사용
df = pd.DataFrame(cancer.data, columns=cancer.feature_names)
df['label'] = cancer.target #cancer데이터의 target을 label이란 컬럼에 저장
#새롭게 만든 컬럼은 항상 df의 맨 뒤(아래)에 있음을 확인해서 아래처럼 인덱싱
X = df.iloc[:, :-1]; y = df.iloc[:, -1] #y에는 타겟데이터만
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
model = LGBMClassifier(random_state=0, max_depth=3, learning_rate=0.01, n_estimators=400)
model.fit(X_train, y_train) #모델 생성 후 학습시키기
print(model.score(X_train, y_train), model.score(X_test, y_test)) #0.9906 0.9790
sns.barplot(x=model.feature_importances_, y=cancer.feature_names) #특성 중요도 시각화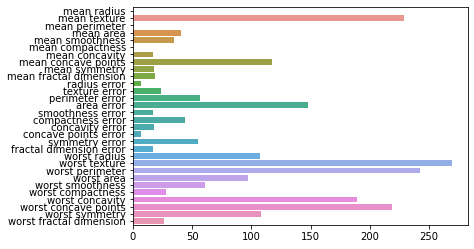
- LightGBM: XGBoost보다 소요 시간과 메모리 사용량이 적으나 데이터 세트의 크기가 작으면(10000개 이하) 과적합 발생. 균형 트리 분할(Level Wise)방식이 아닌 리프중심 트리 분할(Leaf Wise)방식 사용.
- 리프중심 트리 분할: 트리의 균형을 맞추지 않고 손실값이 큰 리프노드를 지속적으로 분할해 나가는 것. 반복할수록 균형 트리 분할보다 예측 오류 손실이 적어짐
from sklearn.ensemble import StackingClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from xgboost import XGBClassifier
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import StratifiedKFold
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer() #유방암 데이터
X = cancer.data; y = cancer.target
base_models = [] #베이스모델(예측결과)들을 담을 빈 리스트
base_models.append(('lr', LogisticRegression())) #베이스1: 로지스틱회귀
base_models.append(('xgb', XGBClassifier())) #베이스2: XGB분류기
base_models.append(('rf', RandomForestClassifier())) #베이스3: 랜덤포레스트분류기
meta_model = LogisticRegression() #메타모델: 로지스틱 회귀
model = StackingClassifier(estimators=base_models, final_estimator=meta_model)
#스태킹분류기(estimators=베이스모델들, 최종estimator=메타모델)
kfold = StratifiedKFold(n_splits=5) #fold수 5인 stratifiedKFold 만듦
scores = cross_val_score(model, X, y, cv=kfold) #model cv를 5로 해서 스태킹 결과 확인
print(scores, scores.mean()) #[0.9649 0.9473 0.9912 0.9824 0.9823] 0.9736스태킹Stacking: 모든 결과를 취합해 만든 모델로 학습
- 모든 데이터를 사용해 예측한 '기본 수준'모델과 기본 수준을 입력으로 받아 최종 예측하는 '메타 수준'모델 두 가지가 결합된 형태.
- 메타 모델은 예측을 입력으로 받기 때문에 간단한 모델(회귀: 선형회귀, 분류: 로지스틱회귀)을 사용
from sklearn.model_selection import cross_val_score
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_validate
iris = load_iris() #아이리스 데이터 사용
X = iris.data; y = iris.target
model_lr = LogisticRegression() #로지스틱 회귀 모델
model_tree = DecisionTreeClassifier(random_state=0) #결정트리 모델
scores = cross_val_score(model_lr, X, y)
print('lr:', scores, scores.mean()) #cross_val_score로 로지스틱 결과
#lr: [0.96666667 1. 0.93333333 0.96666667 1. ] 0.9733
scores = cross_val_score(model_tree, X, y)
print('tree:', scores, scores.mean()) #cross_val_score로 결정트리 결과
#tree: [0.96666667 0.96666667 0.9 0.96666667 1. ] 0.9600
res = cross_validate(model_tree, X, y, cv=5, return_train_score=True)
res #cv(분할)마다 테스트에 걸린 시간, test/train score를 알려줌
#{'fit_time': array([0.0021503 , 0.00271678, 0.00145316, 0.00088167, 0.00081229]),
#'score_time': array([0.00053191, 0.00051689, 0.00045037, 0.00034094, 0.00027418]),
#'test_score': array([0.96666667, 0.96666667, 0.9 , 0.96666667, 1. ]),
#'train_score': array([1., 1., 1., 1., 1.])}교차 검증(Cross validation): 일반화 성능 향상을 위해 사용. `cross_val_score()` 또는 `cross_validate()`
- 모델의 데이터 민감성을 이해하고 효율적으로 데이터를 사용하기에는 좋지만 폴드 수만큼의 추가적인 연산 비용이 듦
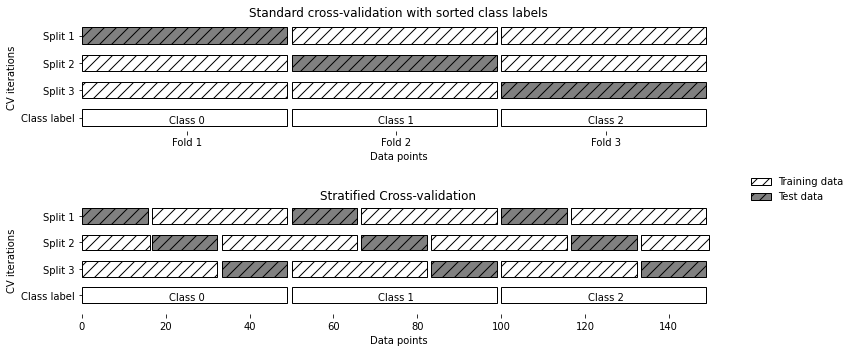
- 폴드 내 비율이 전체 비율과 같아야 보다 정확한 모델이 만들어 질 수 있음

- 위 사진은 10개의 데이터에서 train_size=5, test_size=2, n_splits=4일때의 shufflesplit. 임의분할 교차검증shuffle-split cross-validation은 반복 횟수(n_splits)를 훈련/테스트 세트 크기와 독립적으로 조절할 때 사용. 대규모 데이터를 다룰 때 좋음

- 데이터 안에 연관된 그룹이 있을 경우 그룹별 교차검증groups cross-validation사용. groups라는 레이블 값이 위 사진처럼 [0, 0, 0, 1, 1, 1, 1, 2, 2, 3, 3, 3]일 때 레이블 기반으로 test set을 설정한 것.
- 반복 교차검증: 데이터 크기가 작을 때 사용. RepeatedKFold(회귀), RepeatedStratifiedKFold(분류)
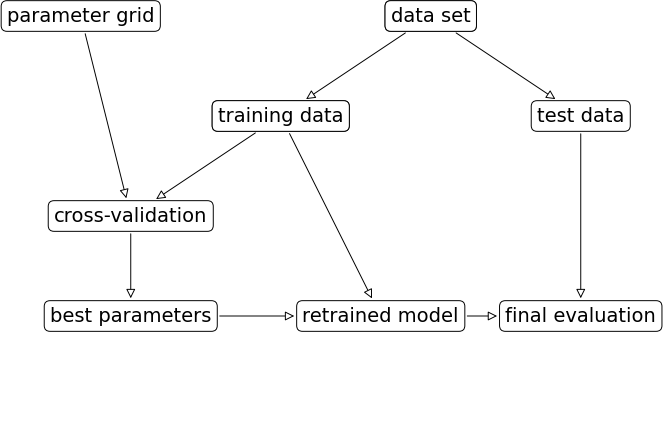
그리드 서치Grid Search: 관심있는 (하이퍼)파라미터를 대상으로 가능한 모든 조합을 시도해보는 것 (일종의 브루트포스?)

- 검증 세트validation set: 모델의 매개변수를 선택(조정)하는 데에 사용되는 데이터셋. 최적의 매개변수를 찾기 위해 가능한(선택할) 파라미터 값들을 리스트로 주고 반복문을 돌려가며 성능(score)을 비교함.
param_grid = {'C': [0.001, 0.01, 0.1, 1, 10, 100],
'gamma': [0.001, 0.01, 0.1, 1, 10, 100]} #param_grid 설정 후
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
grid_search = GridSearchCV(SVC(), param_grid=param_grid, cv=5,
return_train_score=True) #GridSearchCV 만듦
print(grid_search) #위의 param_grid로 묶은 딕셔너리들이 다 들어가있음!
iris = load_iris(); X = iris.data; y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
grid_search.fit(X_train, y_train) #train데이터를 GridSearch모델에 학습
print(grid_search.score(X_test, y_test)) #test데이터에 대한 스코어 확인 #0.9736
print(grid_search.best_score_, grid_search.best_params_)
#best_scores_점수는 교차검증의 평균 정확도 #0.9731 {'C': 10, 'gamma': 0.1}
import pandas as pd; import numpy as np; import mglearn
df = pd.DataFrame(grid_search.cv_results_)#cv_results_를 데이터프레임으로
scores = np.array(df.mean_test_score).reshape(6, 6) #교차검증 평균점수를 array로
mglearn.tools.heatmap(scores, xlabel='gamma', xticklabels=param_grid['gamma'],
ylabel='C', yticklabels=param_grid['C']) #히트맵 그리기
(best_params_였던 'C':10, 'gamma':0.1의 교차검증 평균점수가 제일 높음을 알 수 있음(0.97))
- GridSearchCV의 fit()은 1)최적의 매개변수를 찾아 2)교차검증 성능이 가장 좋은 매개변수로 모델을 만듦
- predict, score, predict_proba, decision_function 사용이 가능하므로 best_estimatror를 쓸 필요가 없음
- 랜덤 서치RandomizedSearchCV: GridSearchCV 사용 시 할 일이 너무 많을 때 사용
모델 평가
- 분류에는 정확도, 오차행렬, 분류 리포트, 정밀도, 재현율, f1 score, 정밀도-재현율 곡선(ROC-AUC curve) 등이 있음

- 정확도Accuracy: 전체 데이터 중 예측 결과가 맞은 비율(왼쪽 그림에서 전체 데이터 대비 True Negative와 True Positive를 더한 비율)
- 오차행렬Confusion matrix: 분류 모델의 예측이 어떻게 되었는지를 나타내는 지표. True/False는 실제 값이 예측 값과 같은지/다른지, Positive/Negative는 (모델의)예측이 긍정인지/부정인지를 의미.
- 분류 리포트Classification report: 정밀도, 재현율,
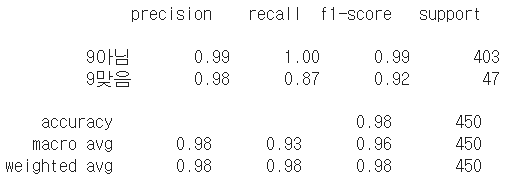
f1-score를 한번에 출력해 주는 것. 정밀도는 True Positive / False Positive + True Positive (=False Positive의 비율을 줄이고자 하는 것)이고, 재현율은 True Positive / False Negative + True Positive(=False Negative의 비율을 줄이고자 하는 것). f1-score는 정밀도*재현율/정밀도+재현율로, 조화평균이라 불림.
- ROC-AUC: ROC는 False Positive Rate이 바뀔 때 True Positive Rate이 어떻게 변하는지를 나타내는 그래프, AUC는 ROC 곡선 아래의 면적. (FPR: FP/TN+FP(실제로 negative인 것 중 positive라 잘못 예측했던 비율), TPR:TP/FN+TP(실제로 positive인 것 중 positive라 잘 예측한 비율). FPR은 낮을수록 좋고, TPR은 높을수록 좋다.) AUC점수가 높을수록 좋은 모델이라고 볼 수 있음
- 결정함수는.. 존재는 알겠지만 왜 쓰는지 모르겠어서 패스..ㅎ
- 회귀에는 평균제곱오차(MSE), 평균절대값오차(MAE), 결정계수, RMSE(MSE에 루트), MSLE(MSE에 로그) 등으로 평가
구름 프로젝트랑 개인(팀) 프로젝트가 겹쳐서 정신도 없고.. 힘들어요 삉삉쁭삉삉ㅠㅠㅠㅠㅠ
'STUDY' 카테고리의 다른 글
| 파이썬 스터디 ver3. 10주차 (4) | 2022.09.19 |
|---|---|
| 파이썬 스터디 ver3. 9주차 (3) | 2022.08.26 |
| 파이썬 스터디 ver3. 7주차 (2) | 2022.08.14 |
| 파이썬 스터디 ver3. 6주차 (3) | 2022.08.06 |
| 파이썬 스터디 ver3. 5주차 (0) | 2022.07.30 |



