2022.08.15~2022.08.19
구름 X 전주 ict 이노베이션 스퀘어의 온라인 코딩교육 내용을 정리하였습니다.
사실 저 기간은 아니지만.. 이번 프로젝트(세미프로젝트 3)로 정리해보겠습니다.
3차 팀프로젝트: 편의점 간편식 추천 (데이터 출처: 식품영양성분 DB 크롤링, 스크레이핑)
df = pd.read_excel('/content/drive/MyDrive/Colab Notebooks/구름 프로젝트/FoodListExcel_20220822093231.xlsx',
index_col='식품명')
df.info() #데이터프레임 정보 확인
No와 에너지 kj단위와 총 포화지방산(%)은 크게 필요가 없어 보인다. 칼럼을 아예 드랍하자
df = df.drop(['No.', '에너지(kj)', '총 포화 지방산(%)'], axis=1)
df.info()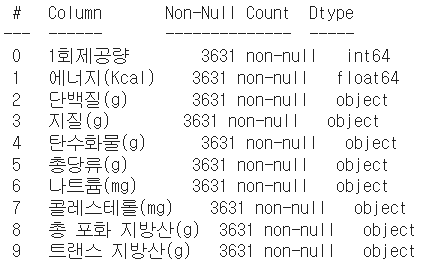
컬럼 세개가 잘 지워졌음을 확인할 수 있다. 그러나 컬럼 타입들이 마음에 안 든다 (단백질부터는 다 object type..)
df = df.replace('-', 0.0)
df = df.astype('float')
df = df.astype({'1회제공량': int})
df.head()
그래서 확인해보니 결측치가 -로 표시되어 있었다. -를 0.0으로 바꾸고 astype으로 전체 컬럼을 float형(1회 제공량만 int)으로 바꿔주었따! df.info()를 하면 1회 제공량을 제외한 모든 컬럼의 dtype이 float64가 되어있다.
이 식품들을 몇 개의 군집으로 나누어보고 싶은데 원본 데이터에 타깃값이 없어 군집화를 통해 군집을 나누어 보고자 한다.
from pandas.core.common import random_state
from sklearn.cluster import KMeans
kmeans_per_k = [KMeans(n_clusters=k, random_state=0).fit(df) for k in range(1, 10)] #k 수 결정
#엘보우 기법: 클러스터 값 바꿔가며 모델 만들어 학습
ine = [model.inertia_ for model in kmeans_per_k] #여기서 클러스터와 센터의 거리를 재 거리들을 제곱해 더함
plt.plot(range(1, 10), ine, "o-") #k 숫자에 따른 ine의 plot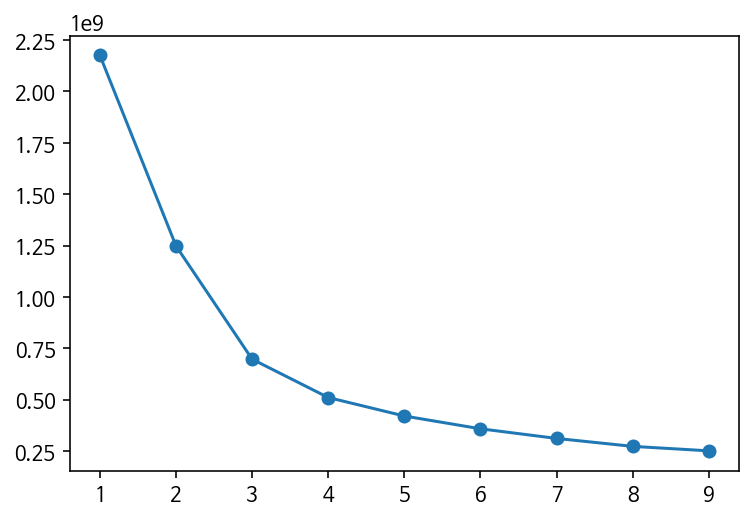
초반에는 큰 폭으로 줄어들다가 4를 기점으로 크게 줄어들지 않는 듯 보인다. k(클러스터 수)를 4로 두면 좋을 것 같다
kmeans = KMeans(n_clusters=4, random_state=0) #모델 만들기
kmeans.fit(df)
kmeans.labels_ #레이블 확인 #array([1, 1, 3, ..., 0, 0, 0], dtype=int32)
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn import metrics
X = df; y = kmeans.labels_ #kmeans로 만든 label값들을 y로 둠
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
print("train 데이터 크기:", X_train.shape) #잘 나뉘었나 확인 #(2723, 10)
print("test 데이터 크기:", X_test.shape) #(908, 10)전체 데이터가 X_train, X_test, y_train, y_test로 잘 나누어 진 것 같다.
그러나 위에서 보았다 싶이, 데이터들의 단위가 다 같지 않아 정규화/표준화가 필요할 것 같다.
from sklearn.preprocessing import MinMaxScaler #Min-max 사용 시
minmax = MinMaxScaler(); minmax.fit(X_train) #scaler 만들기
X_train_scaled = minmax.transform(X_train) #scaler에 맞게 변형
X_test_scaled = minmax.transform(X_test)
from sklearn.svm import SVC #score확인을 위한 SVC model
svc = SVC(gamma='auto').fit(X_train_scaled, y_train)
print(svc.score(X_train_scaled, y_train)) #0.82519
print(svc.score(X_test_scaled, y_test)) #0.83149from sklearn.preprocessing import StandardScaler #SC 사용시
sc = StandardScaler(); sc.fit(X_train) #scaler 만들기
X_train_scaled = sc.transform(X_train) #scaler에 맞게 변형
X_test_scaled = sc.transform(X_test)
from sklearn.svm import SVC #score확인을 위한 SVC model
svc = SVC(gamma='auto').fit(X_train_scaled, y_train)
print(svc.score(X_train_scaled, y_train)) #0.97429
print(svc.score(X_test_scaled, y_test)) #0.96806 #정규화 채택svc모델을 통해 score를 비교해 본 결과, MinMaxScaler보단 StandardScaler의 점수가 더 높게 나왔다. SC를 이용해보쟈
X_train_scaled = round(pd.DataFrame(X_train_scaled), 5)
X_train_scaled.set_index(X_train.index, inplace=True)
X_train_scaled.columns = X_train.columns #scaled된 df
X_test_scaled = round(pd.DataFrame(X_test_scaled), 5)
X_test_scaled.set_index(X_test.index, inplace=True)
X_test_scaled.columns = X_test.columns #test data도 똑같이 df로 만듦X_train_ = X_train_scaled.copy()
X_train_['target'] = y_train #y_train값을 target이라는 컬럼으로 지정
for i in range(4):
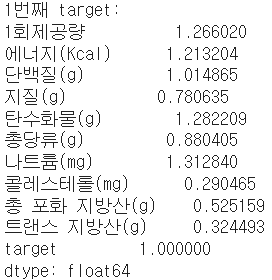
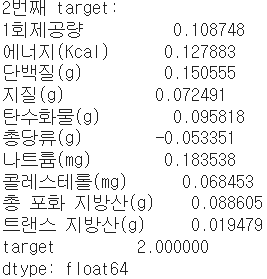
print(f"{i}번째 target:") #각 target별 특징 보기(평균)
print(X_train_[X_train_['target']==i].mean(axis=0))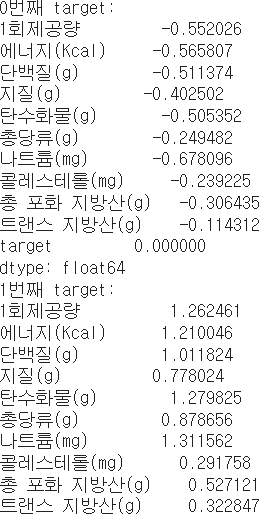
데이터가 요런 식..인데 복붙할 걸.. 뒤늦게 후회되네요
괜히 캡쳐해서 애매하게 짤라버리기..^^
하튼 물론 이 자료로는 안 보이지만.. 이 train 데이터가 standard scaler를 적용한 데이터임에도 불구하고 target값 3들은 기괴하도록 높은 수치들을 가지고 있습니다.
`X_train_[X_train_['target']==3]`으로 df를 확인해보면 더욱 명확해요.
자세히 보면, 용량이 비정상적으로 많습니다. 작은 컵에 담긴 샐러드가 아닌, 벌크 샐러드인 것 같아요. 고의적으로 이렇게 기록한 것일진 모르겠지만 현 프로젝트의 목표가 "편의점 간편식 추천"이기에 저걸 포함하고 간다는 게 맞지 않다 생각됩니다.
(편의점에서 한끼 대용으로 벌크사이즈 콘샐러드를 먹는 사람은 드물지 않을까요..?)
#살펴보니 label=3은 대용량 샐러드가 대부분인 것 같다. #드랍하자
drops = X_train_[X_train_['target']==3].index
X_train_ = X_train_.drop(drops) #인덱스들을 찾아 드랍
print(X_train_.shape) #제대로 드랍되었나 확인 #(2686, 11)
X_train_scaled.drop(drops, inplace=True) #scaled data에도 드랍
print(X_train_scaled.shape) #X_train_의 shape와 (로우)같음 확인 #(2686, 10)
y_train = X_train_['target'] #3을 삭제한 상태인 X_train_의 target을 y_train으로
y_train.value_counts() #0이 1210, 1이 318, 2가 1158로 3이 사라져있음X_test_ = X_test_scaled.copy() #test data에도 마찬가지로 적용
X_test_['target'] = y_test #기존의 y_test값을 X_test_의 target컬럼으로
for i in range(4):
print(f"{i}번째 target:") #target값별 특징 보기(평균)
print(X_test_[X_test_['target']==i].mean(axis=0))
drops = X_test_[X_test_['target']==3].index
X_test_ = X_test_.drop(drops) #target값 3인 친구들 드랍
print(X_test_.shape) #형태 확인 #(891, 11)
X_test_scaled.drop(drops, inplace=True)
print(X_test_scaled.shape) #로우 같음(잘 지워졌나) 확인 #(891, 10)
y_test = X_test_['target']
y_test.value_counts() #0이 405, 1이 98, 2가 388로 3이 사라져있음이렇게 train data, test data에서 target이 3인 친구들을 모두 삭제해주었습니다. y값 또한 헷갈리지(?) 않도록 target이 3인 친구들을 모두 삭제한 df의 컬럼값을 사용했어요.
for i in range(3): #다시 컬럼별 (수치적)특징(평균) 확인~~~
print(f"{i}번째 target:")
print(X_train_[X_train_['target']==i].mean(axis=0))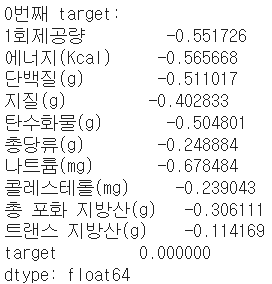
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
pca = PCA(n_components=2) #2차원으로 줄일 예정
pca.fit(X_train_scaled) #표준화 한 데이터를 학습시킴
X_pca = pca.transform(X_train_scaled) #변형시키기
print(X_pca.shape) #2차원 데이터가 되었음
plt.scatter(X_pca[:,0], X_pca[:,1], c=y_train)
plt.xlabel("주성분 1"); plt.ylabel("주성분 2"); plt.show()
#이상치가 있어 보인다.. 지워서 다시 해봐야 할 것 같다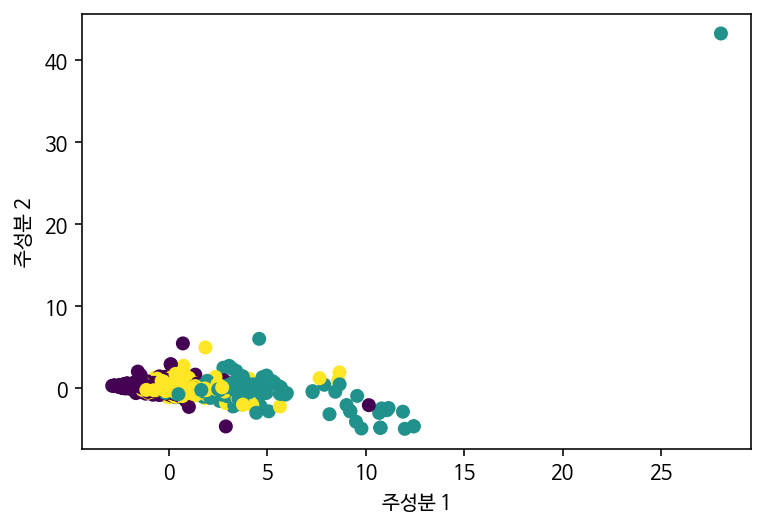
오른쪽 위의 점은 누가 봐도 이상치입니다.. 무엇 때문일까, 어떻게 볼 수 있을까, 하다 기존의 scaled된 data에서 찾아보기로 했습니다. (지금 와서 생각해보면 그냥 X_pca에서 찾아도 됐었을 것 같긴 합니다..)
for i in X_train_scaled.columns:
print(X_train_scaled[i].describe())
#컬럼별 수치요약통계 확인: 트랜스지방과 포화지방이 타 데이터 대비 max와의 격차가 큼
print(X_train_scaled.shape) #현재 shape 확인(로우 몇 개를 삭제할 예정이기 때문) #(2686, 10)
f1 = X_train_scaled[X_train_scaled['트랜스 지방산(g)'] == X_train_scaled['트랜스 지방산(g)'].max()].index
X_train_scaled.drop(f1, inplace=True); y_train.drop(f1, inplace=True)
f2 = X_train_scaled[X_train_scaled['총 포화 지방산(g)'] == X_train_scaled['총 포화 지방산(g)'].max()].index
X_train_scaled.drop(f2, inplace=True); y_train.drop(f2, inplace=True) #둘 다 index확인 후 drop
print(X_train_scaled.shape) #(2684, 10) #로우 두 개가 잘 삭제되었음 확인트랜스 지방과 총 포화지방 또한, 위와 마찬가지로 이런 (건강에 좋지 않은) 식품을 추천하는 건 맞지 않다고 봐서 과감히 삭제했습니다.
#이상치 제거 후 차원축소 시도
pca = PCA(n_components=2)
pca.fit(X_train_scaled)
X_pca = pca.transform(X_train_scaled)
print(X_pca.shape)
plt.scatter(X_pca[:,0], X_pca[:,1], c=y_train)
plt.xlabel("주성분 1"); plt.ylabel("주성분 2"); plt.show()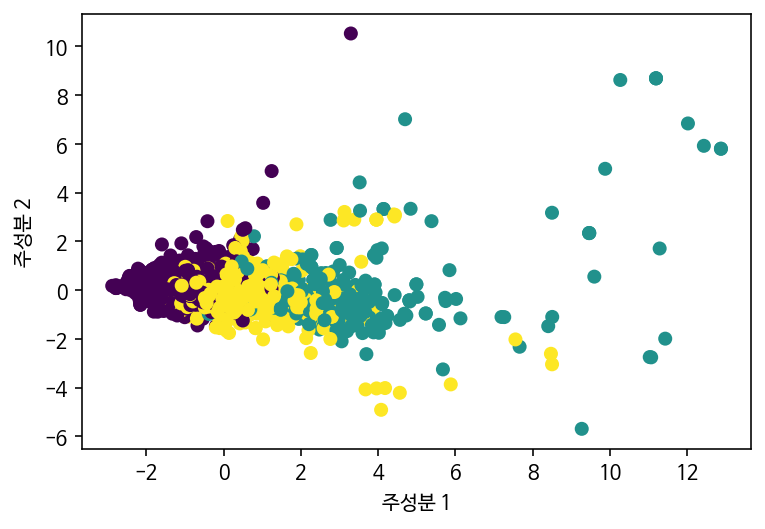
이상치(로 추정되는 값) 두 개만 삭제했을 뿐인데 나름 괜찮아 보입니다..? 잘 나뉜 것 같아요.
x_ = sc.inverse_transform(X_train_scaled) #표준화 되돌리기
x_ = round(pd.DataFrame(x_), 5) #소수점 5째자리까지 표시
x_.set_index(X_train_scaled.index, inplace=True)
x_.columns = X_train_scaled.columns #인덱스, 컬럼 설정
x_['레이블'] = y_train #y_train값이었던 것을 레이블이라는 컬럼으로 만듦
x_ = x_.replace({'레이블':{0:"가벼운 음식", 1:"고영양 음식", 2:"일반 음식"}})
#0부터 2까지의 숫자 값이었던 label을 가벼운/고영양/일반 음식이라 대체
x__ = sc.inverse_transform(X_test_scaled) #test데이터에도 마찬가지로 실행
x__ = round(pd.DataFrame(x__), 5)
x__.set_index(X_test_scaled.index, inplace=True)
x__.columns = X_test_scaled.columns
x__['레이블'] = y_test
x__ = x__.replace({'레이블':{0:"가벼운 음식", 1:"고영양 음식", 2:"일반 음식"}})
data = pd.concat([x_, x__])
data #2684+890 = 3574 #X_train_scaled는 2684개 행, X_test_scaled는 890개 행
표준화 시켰던 것도 잘 되돌아왔고, 데이터프레임 합치기도 성공적으로 된 듯 합니다.
이제 추천시스템을 구현.. 하고 싶었지만 사실 아직 추천 시스템에 대해 거의 배우지 못했기에 방향을 꺾었어요! 랜덤으로 음식을 뽑아주는 함수를 만들면 좋겠다 싶었습니다.
import random
light_menus = data[data['레이블']=='가벼운 음식'].index
selected = random.choice(light_menus) #랜덤으로 1개를 선택해
print(selected); print(data.loc[selected][:-1]) #data df에서 출력
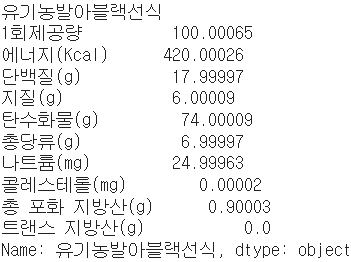
요런 식입니다. [:-1]은, 맨 마지막 컬럼이 '레이블'컬럼이었기 때문에 빼고 출력했습니다. 이걸 아예 함수로 만들면
import random
def food_cu(): #뒤늦게 안 건데, 이 데이터 cu말고도 다른 편의점 것들도 많더라구요...
a = input("가벼운 음식, 일반 음식, 고영양 음식 중 하나를 입력해주세요:")
if a == "가벼운 음식":
light_menus = data[data['레이블']=='가벼운 음식'].index
selected = random.choice(light_menus)
print(selected); print(data.loc[selected][:-1])
elif a == "일반 음식":
light_menus = data[data['레이블']=='일반 음식'].index
selected = random.choice(light_menus)
print(selected); print(data.loc[selected][:-1])
elif a == "고영양 음식":
light_menus = data[data['레이블']=='고영양 음식'].index
selected = random.choice(light_menus)
print(selected); print(data.loc[selected][:-1])
else:
a = input("가벼운 음식, 일반 음식, 고영양 음식 중 하나를 입력해주세요:")food_cu()라는 함수를 실행시키면 "가벼운 음식, 일반 음식, 고영양 음식 중 하나를 입력해주세요:"라는 창이 뜹니다. 이 입력창에 입력하는 값(a)에 따라 레이블이 '가벼운 음식'의 인덱스를 가져올 지, '고영양 음식'의 인덱스를 가져올지가 결정됩니다. print문은 위에서 보셨던 것과 마찬가지로 제품 이름과 제품의 영양성분을 출력해줍니다.
def foods_cu(): #음식 5개 추천(랜덤으로 뽑기)
a = input("가벼운 음식, 일반 음식, 고영양 음식 중 하나를 입력해주세요:")
rec = pd.DataFrame()
if a == "가벼운 음식":
for i in range(5):
menus = data[data['레이블']=='가벼운 음식'].index
selected = random.choice(menus)
rec = rec.append(data[data['레이블']=='가벼운 음식'].loc[selected])
rec = rec.drop('레이블', axis=1)
rec = rec.loc[~rec.index.duplicated(keep='first')]
fig, axes = plt.subplots(1, 2)
rec[['나트륨(mg)', '에너지(Kcal)']].plot(kind='bar', ax=axes[0])
rec[['탄수화물(g)', '단백질(g)', '지질(g)']].plot(kind='bar', ax=axes[1])
plt.legend(bbox_to_anchor=(1, 1)); plt.tight_layout()
return rec
elif a == "일반 음식":
for i in range(5):
menus = data[data['레이블']=='일반 음식'].index
selected = random.choice(menus)
rec = rec.append(data[data['레이블']=='일반 음식'].loc[selected])
rec = rec.drop('레이블', axis=1)
rec = rec.loc[~rec.index.duplicated(keep='first')]
fig, axes = plt.subplots(1, 2)
rec[['나트륨(mg)', '에너지(Kcal)']].plot(kind='bar', ax=axes[0])
rec[['탄수화물(g)', '단백질(g)', '지질(g)']].plot(kind='bar', ax=axes[1])
plt.tight_layout()
return rec
elif a == "고영양 음식":
for i in range(5):
menus = data[data['레이블']=='고영양 음식'].index
selected = random.choice(menus)
rec = rec.append(data[data['레이블']=='고영양 음식'].loc[selected])
rec = rec.drop('레이블', axis=1)
rec = rec.loc[~rec.index.duplicated(keep='first')]
fig, axes = plt.subplots(1, 2)
rec[['나트륨(mg)', '에너지(Kcal)']].plot(kind='bar', ax=axes[0])
rec[['탄수화물(g)', '단백질(g)', '지질(g)']].plot(kind='bar', ax=axes[1])
plt.tight_layout()
return rec
else:
a = input("가벼운 음식, 일반 음식, 고영양 음식 중 하나를 입력해주세요:")빈 데이터프레임을 만들어 append로 음식을 하나씩 총 다섯 개를 넣어 준 뒤, 완성된 데이터프레임과 '나트륨, 에너지'와 '탄수화물, 단백질, 지질'의 바플랏을 보여줍니다.

최종 결과물이 이런 식인거죠. 참고로 저 글자들을 예쁘게 엔터치는 방법이 없을까 찾아보았는데... 제 구글링 실력으로는 알 길이 없었습니다. 아시는 분 있으시면 가르쳐주시면 감사하겠습니다...
'STUDY' 카테고리의 다른 글
| 파이썬 스터디 ver3. 11주차 (2) | 2022.10.03 |
|---|---|
| 파이썬 스터디 ver3. 10주차 (4) | 2022.09.19 |
| 파이썬 스터디 ver3. 8주차 (2) | 2022.08.22 |
| 파이썬 스터디 ver3. 7주차 (2) | 2022.08.14 |
| 파이썬 스터디 ver3. 6주차 (3) | 2022.08.06 |



